
文本预测系统设计
希望设计一个系统,输入一段词汇,希望他预测接下来的内容。
input via word embedding
如何用一个向量vector表示一个字词word的意思(word embedding)?以下是获得vector的几种方法。
理论上可行的办法有以下几种。
1-of-N encoding/one-hot encoding
假设一个有N个字的字典,那么每一个字vector长度都是N。一个word出现就占用对应dimension为1。缺点在于需要预先知道所有的字,很占用内存空间。缺少字与字之间的语义关联性。
可以为未知词汇添加一个dimension’other’,于是上面的1-of-N encoding就可以变成1-of-(N+1) encoding。
用word-hashing。a-a-a/a-a-b等原子,用每一个原子去对应word,可以表示所有英文单词。
Bag of Words(BOW)
将句子里的文字变成一个袋子装这些词,不考虑词的次数和顺序/文法。
具体训练时可以用skip-gram/CBOW等方法获得word embedding,这些层的参数是否要跟着模型一起训练可以通过fix_embedding的T/F来更改。
output as probability distribution
输出我们希望得到一个probability distribution,代表了预测下一个单词出现在系统给定的每一个slot的概率。
input & output are both sequences with the same length.
slot就是一句话的语境意义。某个单词属于某个slot就代表这个单词意味着这句话的有效信息。
例如,Taipei是一个destination slot, November 2nd 是一个time of arrival slot。
并不是每一个单词都会属于某个slot,一句话需要提取出有效信息。
RNN的特殊之处在于,hidden layer中的output都会被存放到memory parameters中去。下一次有input的时候,neuron既会考虑x1/x2,也会考虑memory中存放的数据。因此就算每一次输入相同,输出结果也会不同。
RNN类别
Elman Network
当前输入的每一个hidden layer的输出,都用作下一个输入的对应hidden layer的输入。
Jordan Network
当前输入的最终output保存在memory中,在下一个timestep的下一个输入作为输入考虑。
Bidirectional RNN
同时训练正向和逆向的model,也就是向前看也向后看。
把两个模型中某个timestep的对应输入的hidden layer参数都考虑,然后决定输出。
如何Memory
基本原理
Long short-term Memory(LSTM): 4 input, 1 output.
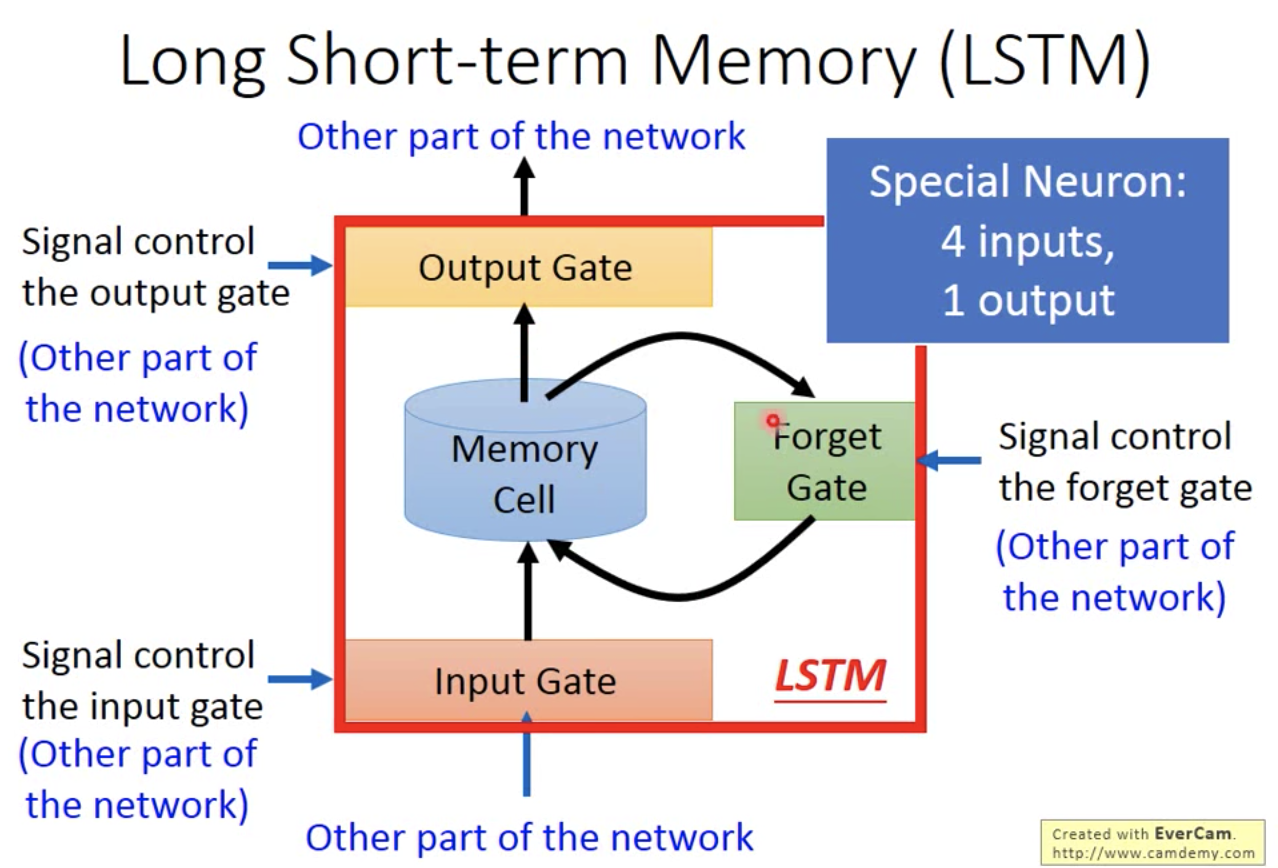
蓝色箭头的四个输入都是vector,这四个输入都是不一样的,从同一个原始x做了不同的线性变换(乘以了不同的权重)后得到的,所以x的维度和四个输入的维度都是一样的,等于memory cell的数目。参数量是4倍。
输入中有三个都是signal control,包括input gate/output gate/forget gate。这三个gate都是由activation function组成的,一般选择sigmoid function,因为它形似0-1开关函数,但是有一个平滑的上升。
输入中有一个是network中的产生memory内容的neuron的输出。
黑色箭头的一个输出都是vector:代表了LSTM这个小nueron的输出。
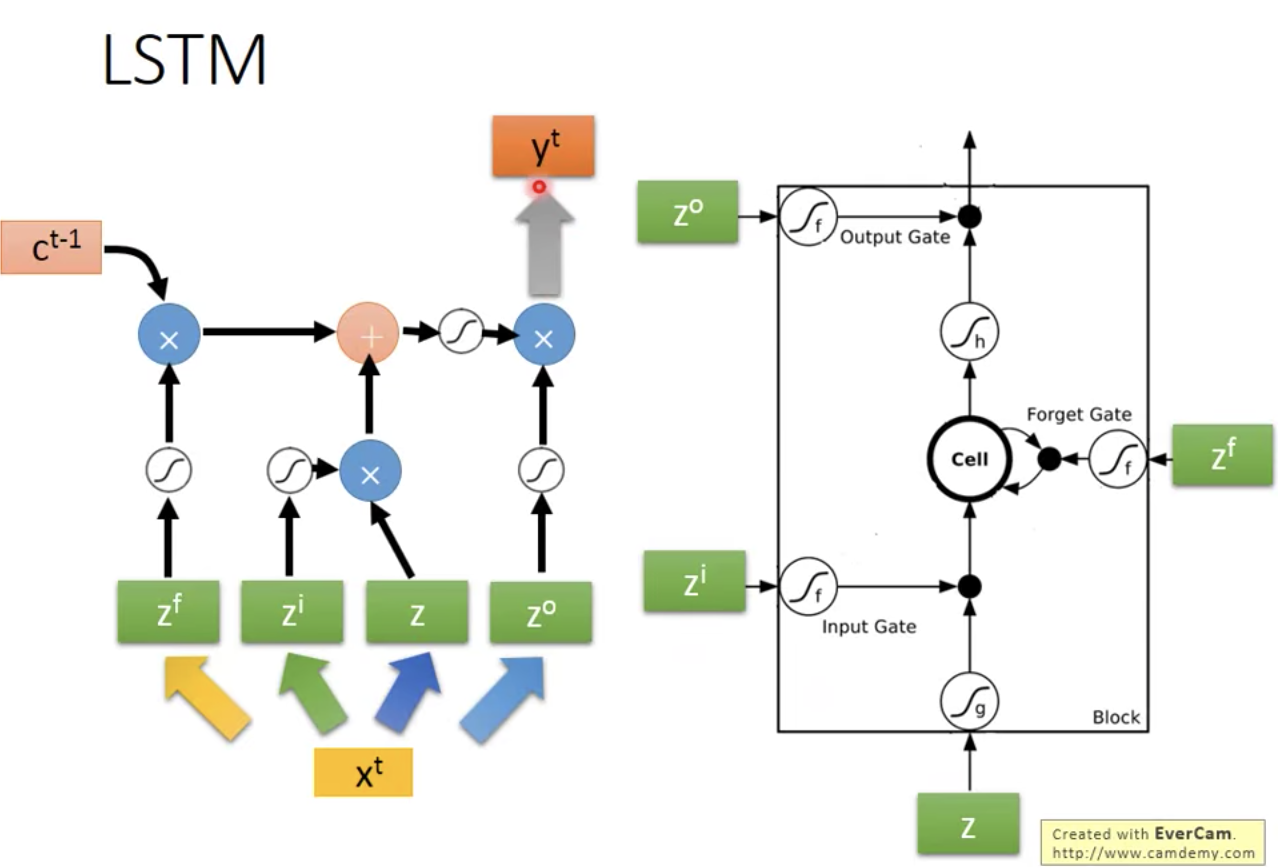
实际输入
但实际在做的时候并不是只有

如何训练
如何定义损失函数?如何表示NN的输出?如何表示实际的输出?
NN的输出
但是问题是当前时间点的一个单词的cross entropy代表的损失函数和最终整个句子的error关系不大(cost & error not always related)。
定义好损失函数之后如何最小化损失函数?
Backpropagation throught time
RNN训练的困难之处在于参数很小的变化可能引起gradient巨大的变化,也可能参数很小的变化对gradient影响根本没有。有点类似于函数中那种跳跃型间断点,在不间断的时候特别平缓,间断的时候又是特别剧烈。
如何解决损失函数崎岖不平,梯度忽大忽小Gradient Vanishing coexist with Gradient Explode的问题?
Long Short-term Memory can handle gradient vanishing(not gradient explode)
理由:Memory and input are added,受input gate和forget gate同时控制,除非forget gate关掉了,那么前一次的memory cell中的内容不会消失,因此就没有梯度消失的问题。
更多应用
Slot Feeding:引入中的例子
Sentiment Analysis:input是sequence的分类问题,所以要用到RNN
Key Term Extraction:input是document sequence
Speech Recognition
input和output都是sequence,但是最终input和output vector的长度不一致。
可能input的好多词都值对应同一个character,那么output需要trimming变成更短的去掉重复内容的character sequence
Machine Translation:input和output都是长度不同的sequences。
Syntactic Parsing:看一个句子得出语义的树状结构,以前要用structure learning。
Sequence-to-sequence auto-encoder — text
input是word sequence,通过RNN变成一个vector — encoder的部分。
把这个vector当作后续decoder的输入,找回一模一样的句子。
如果可以成功做到两个步骤,Encoding的vector就代表这个input sequence的重要的信息,在训练模型的时候就不需要label data了,只需要大量input。
- Sequence-to-sequence auto-encoder — speech
有包含了许多内容的一段语音,你先对他做segmentation切成一段一段,然后用audio segmentation to vector的技术(这里需要用到RNN)把segment变成fixed length vector,这些vector之间的距离代表了他们的相似程度。
- 本文标题:循环神经网络
- 本文作者:徐徐
- 创建时间:2020-11-09 22:11:13
- 本文链接:https://machacroissant.github.io/2020/11/09/rnn/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!