
Improving Supervised Seq2Seq Model
Reinforcement Learning
利用Chat-bot Example来讲解Reinforcement Learning在Seq2Seq Model中的实际应用。
Maximum Likelihood
利用MLE来训练Seq2Seq的model存在问题。使用Maximum Likelihood本质就是在Minimize Cross Entropy。
how are you我们希望chat-bot回答I’m fine但是实际对话中如果一个chat-bot有可能回答not bad和I’m Jone,从人的感觉来看not bad是更好的,但从我们定义的MLE来看,第一个单词I’m和正确回答相匹配,那么I’m Jone这个概率会更好。
Reinforcement Learning
那我们应该用什么方法来判断?Maximizing Expected Reward。Chat-bot是一个系统,和Chat-bot对话的人也是一个系统。Chat-bot依据人给出的Reward反馈update自己的参数,也就是Machine obtains feedback from user。
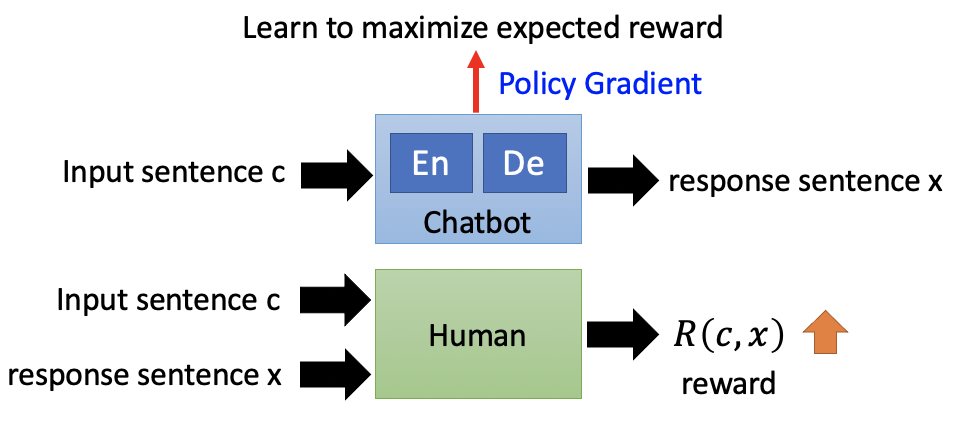
整个系统重新连接一下,可以得到以下的形式。
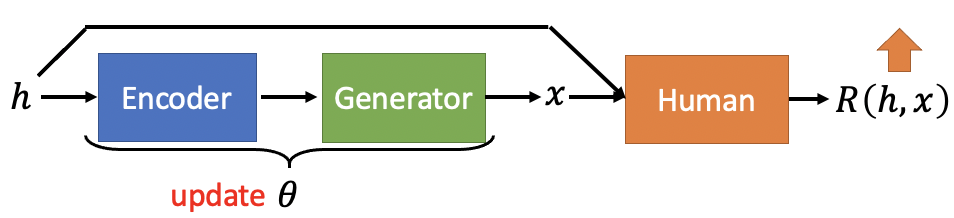
目标是去调整encoder和generator的参数(也就是Seq2Seq model的参数),使得Human的function R的output越大越好。分为两个步骤,如何定义R的output,以及如何去最大化这个output。
定义Reward Function output
如何计算Reward function R的output?对于给定的
summation over all input c,因为各种各样的input出现的几率各不相同。
summation over all feedback given certain output of chat-bot。由于每次给同样的input,对应的output不一定是一样的,对于给定的c,我们得到的x是不一样的,是一个x的probability,chatbot的output本质上就是一个distribution
最大化Reward Function output
Maximizing expected reward就是找一组Seq2Seq模型的参数
改写上一步骤中的式子,写成分布的形式。
虽然目标是要取期望值,但是我们没办法真正获得disribution来获得期望值。我们需要一次approximation,从database里做sample,sample出N笔data,即
等我们做完approximation之后,发现要去update参数theta,但是最后的式子中哪里有theta?theta的值会影响我们从database中sample的N笔data,没法算gradient。
实际操作中先对原式子做gradient,再去做approximation,这样就能把theta保留在我们要去maximize的式子中。
更新参数的操作如下。

每次update参数之后,需要和使用者互动N次获得N笔sampling data的reward之后,再去做policy gradient。
两种比较

Traning Data
Maximum Likelihood中都是人为标注的label,是全部正确的。
Reinforcement Learning中的的数据都是机器自己产生的,有些答案可能是错的。
Gradient
ML中每一笔Traning Data的weight都是一样的。
RL中每一个x和c的pair都乘以了一个Reward,意思就是每一笔Traning Data都有weight。如果data中machine的回答是正确的,那么给它一个positive weight;如果data中machine的回答是错误的,那么给它一个negative weight。
weight有没有可能都是正的?我们希望reward有正有负,一般会对所有正的weight减去一个threshold。
不可能sample到所有的x,对于在一次iteration中没有被sample到的data,他们被sample到的概率会在一次iteration结束后降低。因为总概率总是1,其他被sample到且reward比较大的,被选择的概率就变大了。
GAN
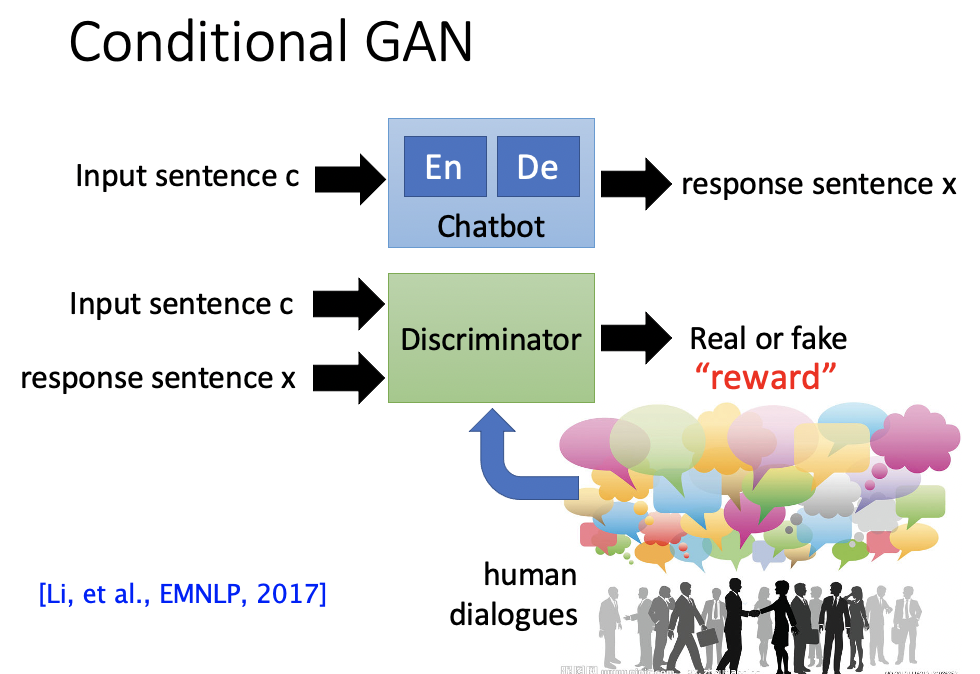
Reinforcement Learning中为了实现一个较好的machine,需要机器与人互动上万次。时间成本与人力成本过高。
因此引入GAN,human中的feedback由Discriminator来给。类似于Conditional GAN。
无法微分的三种解决办法
由于有sampling process,无法将Seq2Seq Model和Discriminator接起来的时候对整个network进行微分。
Gumbel-softmax
Continuous Input for Discriminator
Use the distribution as the input of discriminator to avoid sampling process.
Reinforcement Learning
What
Consider the output of discriminator as reward
Update generator to increase discriminator = to get maximum reward
Using the formulation of policy gradient, replace reward R(c,x) with discriminator output D(c,x)
Different from typical RL in that the discriminator would update
HOW
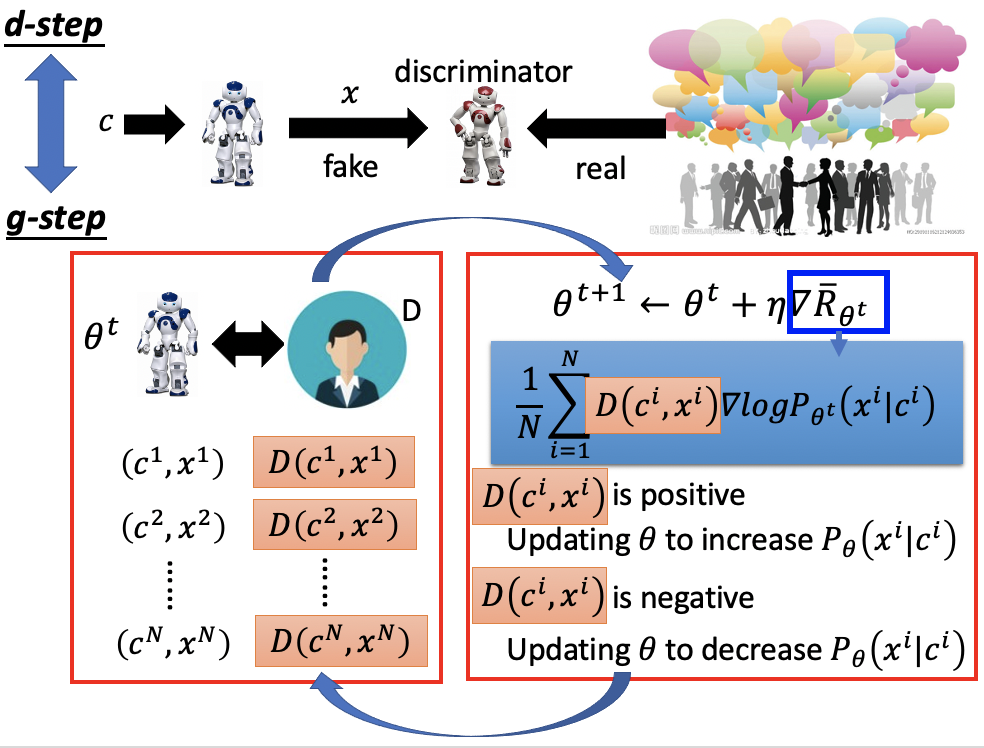
分为两个步骤,一个是训练generator g-step,与前面RL中的训练方法类似;另一个是训练discriminator d-step,要结合实际对话与机器产生的对话。
但是在g-step中每个iteration的objective function在进行update参数之后,目标是要让log函数的概率变低,也就是说我们要让chat-bot对于某个输入x,不怎么好的输出c的概率降低。问题在于这个概率是对整个句子的概率的衡量,而整个句子的概率是通过每一个短语的条件概率相乘/log相加获得的。如果要decrease整个句子,那每个短语的概率也要decrease?

我们希望在计算的时候machine知道整个句子虽然是不好的,但是实际increase或decrease的时候需要句子的某些部分。
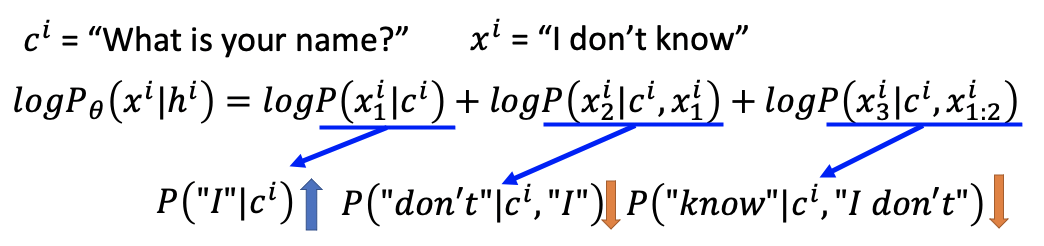
因而我们需要修改objective function,换成在每一个timestamp做evaluation,而不是对整个句子做evaluation。
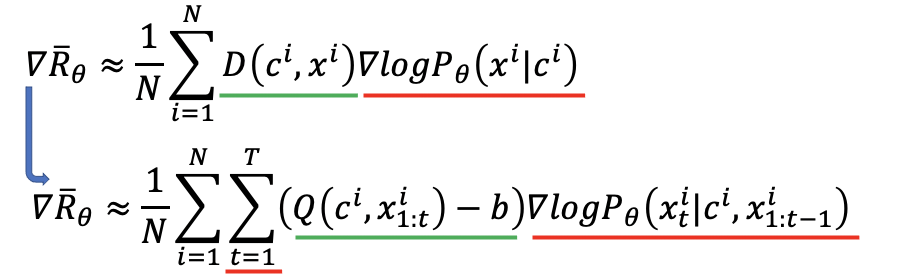
Unsupervised Conditional Sequence Generation
Text Style Transfer
之前看过Image和Voice之间style transfer的例子。对应到text中,可以把positive sentences对应transfer到negative transfer。
用CycleGAN实现。但是还存在discrete无法gradient ascent的问题。需要把对word sequence做word embedding,就变成连续的了。
用Projection to Common Space。
以上都参考GAN Introduction中的内容。
Unsupervised Absractive Summarization
supervised的方法需要收集百万笔的labelled traning data(document1 — summary1),否则machine连产生自己的句子都不能实现(从文章中拿句子当作summary并不算一个好的summarizer)。
所以我们需要unsupervised的方式。利用和CycleGAN差不多的架构。
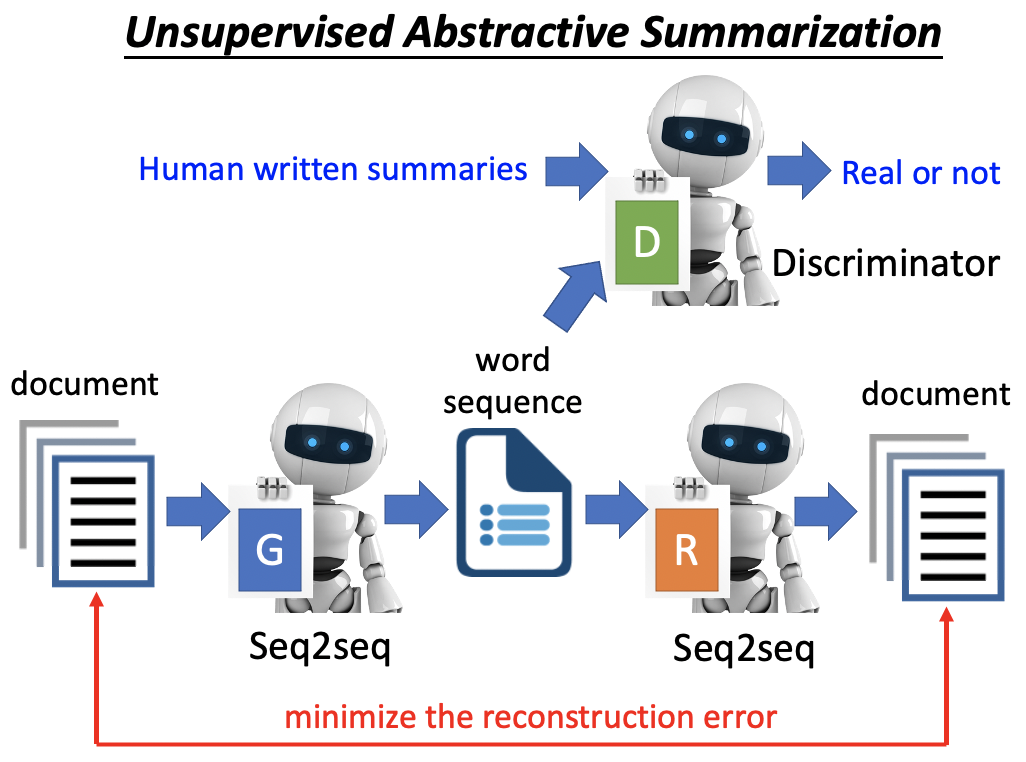
实际上看下面需要Minimize the reconstruction error的部分,本质上是a Seq2Seq2Seq auto-encoder。这个部分找到了document — word sequence — document的一个满足的映射。
这个映射人类是否能读懂呢?需要Discriminator来做限制。
supervised learning是unsupervised learning的upper bound。
我们采用unsupervised的方法的意义在只需要于supervised的方式的data数量的一半就可以达成和supervised的一样的效果。
Unsupervised Translation
利用CycleGAN可以把两种不同的语言间可以直接unsupervised做翻译。
类似的也可以应用到语音辨识中。
- 本文标题:Improve Sequence Generation by GAN
- 本文作者:徐徐
- 创建时间:2020-11-19 08:57:55
- 本文链接:https://machacroissant.github.io/2020/11/19/sequence-generation/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!