
什么是transformer?
Transformer是一个使用了注意力机制Attention使训练速度提升的一个模型。Transformer在谷歌发布的Attention is All You Need一篇文章中被提出,并在TensorFlow的Tensor2Tensor库中实现。Transformer最大的特点就是对于一个输入句子,它可以做到并行处理句子中的每一个词。
把Transformer看作一个黑盒子,他的输入是一句话,输出也是一句话;在这个黑盒子在拆分一下,黑盒内部有Encoders(由许多Encoder顺次连接而成)和Decoders(由许多Decoder顺次连接而成)两部分组成,Input->Encoders->Decoders->Output。
Encoders中每一个Encoder都在架构上类似,但是权重上不同。每一个Encoder的输入首先进入Self-Attention,再进入Feed Forward Neural Network层。Self-Attention的帮助Encoder在encode某个词语的时候考虑这个句子中的其他词语。Feed Forward Neural Network前馈神经网络由一个输入层,一个浅层网络或多个隐藏层,以及一个输出层构成。每一层与下一层连接,可以有不连接的神经元,如果全部连接就是全连接网络了。例如卷积神经网络CNN就是典型的深度前馈神经网络。
Decoders中每一个Decoder都在架构上类似,Decoder和Encoder的区别在于,在Decoder的self-Attention层与Feed Forward层之间有一个Encoder-Decoder Attention,这一层attention用于帮助decoder关注input中的相关部分。
接下来对一个训练好的Transformer模型的工作流程进行讲解。
准备工作:什么是word2vec
word2vec又叫词嵌入,适用于把一个词word变成一个向量vector的算法。每一个词都会转变成一个维度为i的向量,i是一个可以设定的参数,通常来说我们会把i设定为训练数据集中最长的句子。
word2vec会在什么时候派上用场呢?input不会直接就输入到encoder中去,在那之前会进行word2vec,第一个encoder的输入就是词嵌入后维度为i的向量,此后的每一个encoder都接受上一个encoder的输入。
input中每一个词不是一个一个的进入encoder的,而是一起进入的,虽然在self-attention的时候每一个词的处理是有依赖的,但在feed forward的时候词与词的依赖是不存在的,因此在前馈的部分可以体现transformer并行处理的特征。
Encoders详解
Encoder架构:什么是self-attention
一个句子是会有上下文的,比如“狮子不会吃草,因为它是食肉动物”这里的它指代的是什么,对于人来说这个很好理解,对于代码来说这很难。我们希望模型在处理“它”的时候,将“它”和上文的“狮子”联系起来,这就是self-attention的作用,它会让模型在encoding一个词汇的时候更好的考虑语境。
那么如何对input计算self-attention呢?运用的本质是还是矩阵运算。
基础:word-level attention
接下来以word level查看对于某一个词的self-attention如何计算。
第一步,由input embedding vector与三个矩阵
第二步,计算每一个词与其他词之间的score,所获的score是当模型在encode某一个词
第三步,把获得的score都除以根号下key vectors的dimension,这样做是为了获得更稳定的梯度。
第四步,将结果传入softmax,是结果全为正且所有结果相加为1。This softmax score determines how much each word will be expressed at this position.
第五步,将value vector与softmax score的结果相乘,这一步是为了筛选出值得关注的单词并过滤掉没什么价值的单词。相当于每个value vector乘以某个权重。
第六步,将第五步中的weighted value vectors相加,这个结果就是the output of the self-attention layer at this position(for this word)。这一结果会传递到feed-forward neural network中去。
矩阵运算:matrix calculation attention
我们在上一个word-level中以一个单词为基准去计算,如果多个单词的embedding被pack为一个矩阵
输入矩阵
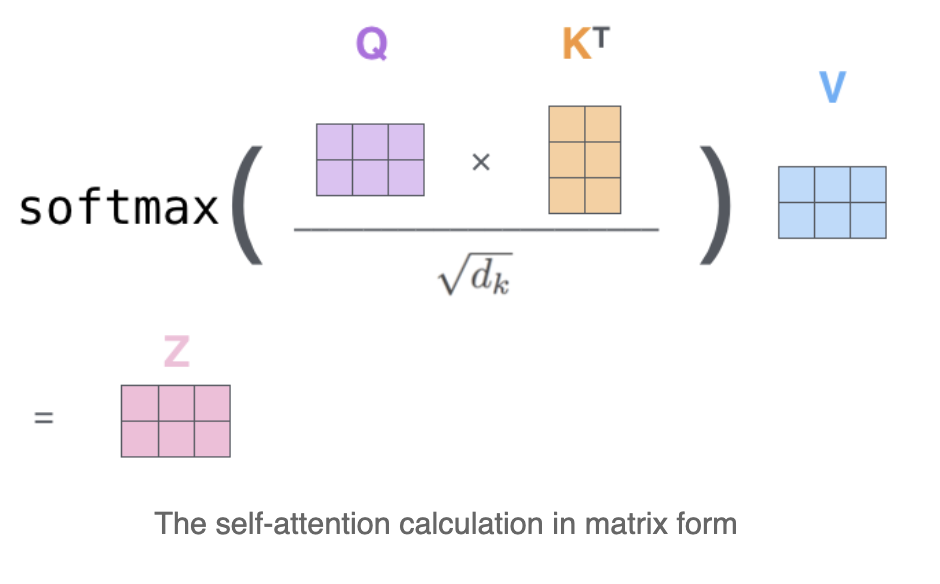
如何理解Q/K/V的关系?用我的搜索(query)快速找到相关内容(Key),并在相关内容上花时间花功夫(Value),得到的结果就是Attention。
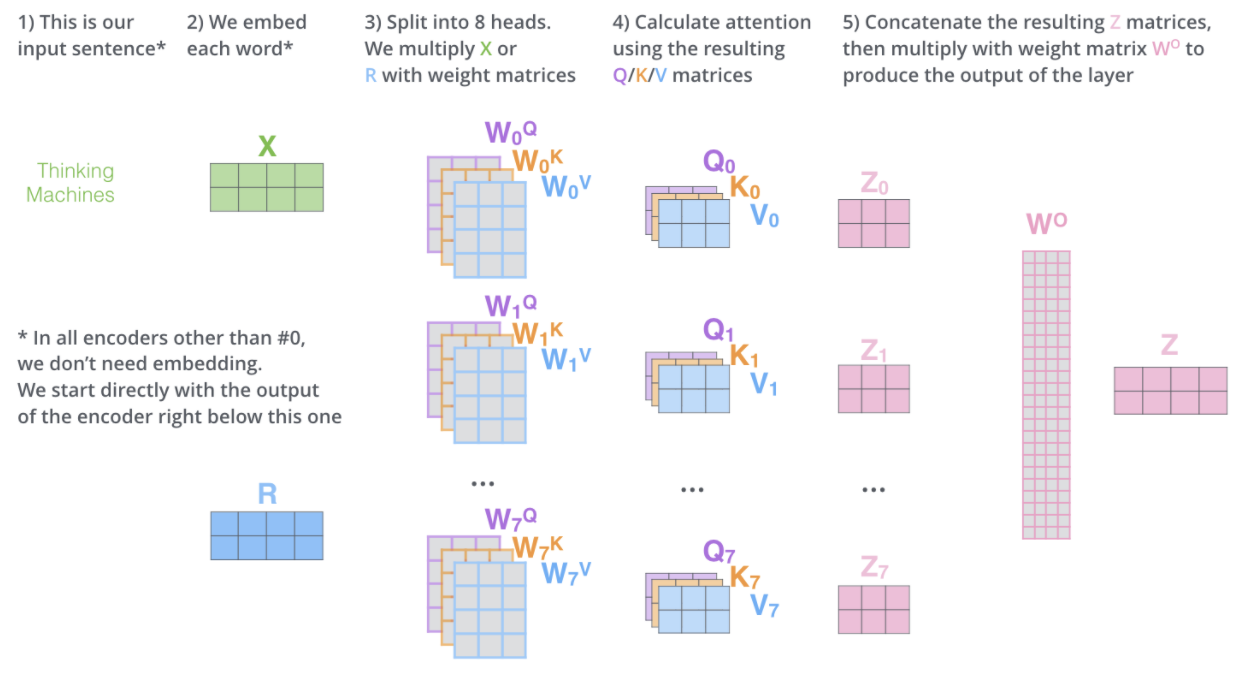
改良:muti-headed attention
muti-headed attention是self-attention的改良。在muti-headed的情况下,可以存在多个随机初始化的Query/Key/Value weight matrices,例如在Transformer中就是用了8个attention head。这些矩阵在训练后,可以用来把我们的embedding input vector用参数矩阵映射到多个子空间——project the input embeddings (or vectors from lower encoders/decoders) into a different representation subspace。
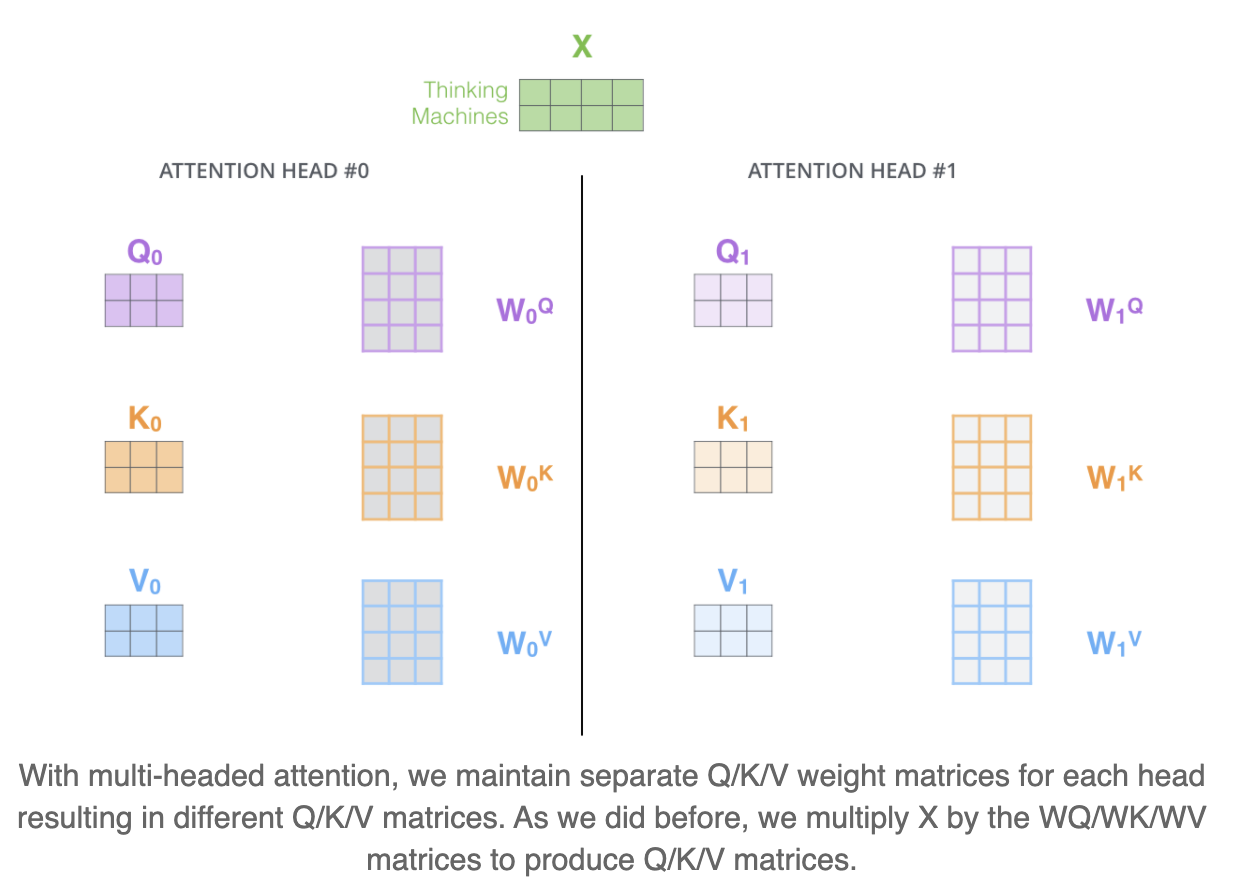
具体来说就是将Q,K,V用h个不同的投影矩阵重复投影h次,分别做h次single-head attention,最后再把结果拼接起来。
代码实现中的问题
在具体的代码实现中,由于tensorflow不会自动并行,所以不能按照multihead的思路来写。需要讲multi-head的操作合并到一个张量来运算。
在实际代码实现中,
但由于投射
由于
解决办法1是不一定要把
解决办法2是Attention计算的内积之后softmax之前用一个参数矩阵叠加多个低秩分布
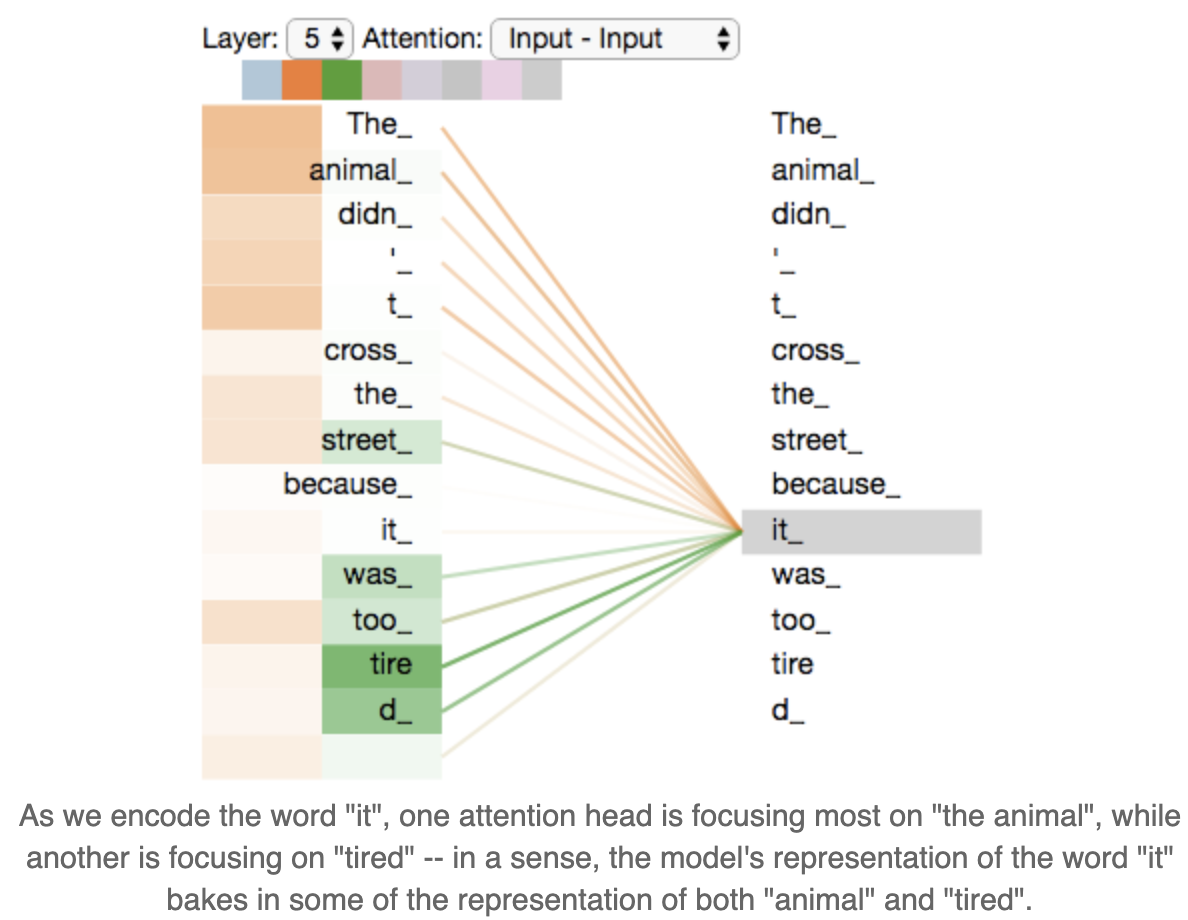
直观理解multi-head
对于”The animal didn’t cross the street because it was too tried”这句话,特定位置的某个单词如it,在每个字空间中,被认为应当focus on的单词都不一样。
multi-head attention后如何去往下一层
按照这样的方式重复多次Q,K,V的计算,可以获得8个Attention head。每一个Z我们都要输入的前馈神经网络去,但是问题在于前馈神经网络只希望获得唯一一个矩阵来代表每一个词。因此我们需要尽可能利用这八个矩阵,并压缩为一个。
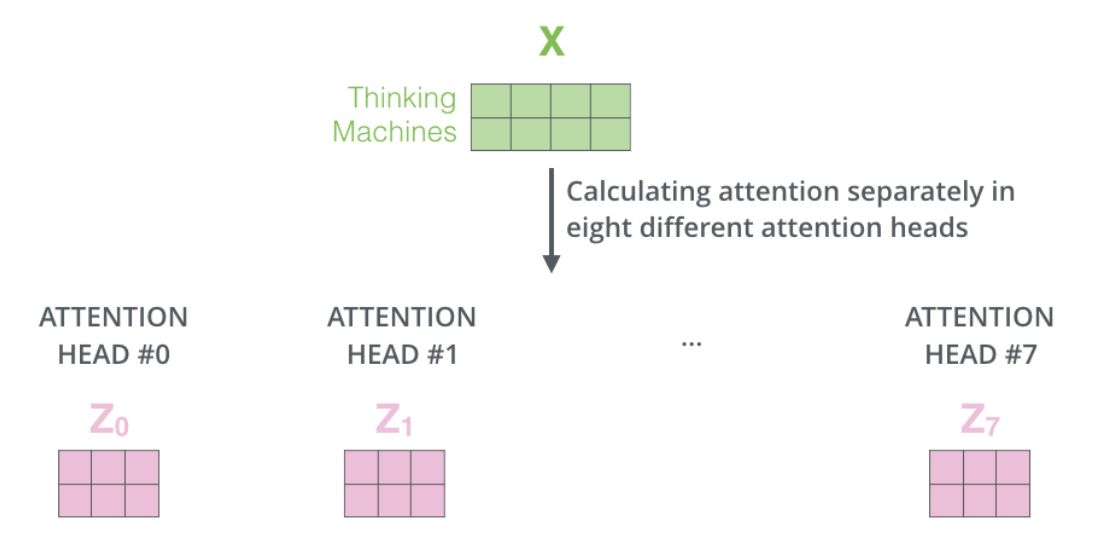
怎么压缩?首先,把所有attention head按顺序拼接起来,注意每一行一个单词,总共就两行,所以拼接过程中总有第一个维度是不能变的。其次,把拼接后的attention heads与一个与模型一起训练的权重矩阵

可以看到这里把muti-head的多个Z的维度又转变了一下。
总结multi-headed attention过程
细节1:如何确定语句序列 Postion Embedding
由于一句话是一个单词的有序排列,我们知道transformer是把每个单词并行输入到FFNN去的,那怎么表示某个单词在句中的位置,或者说怎么判断两个单词在句子中的距离?方法是在输入的单词的embeddings的基础上再加上一个positional encoding。
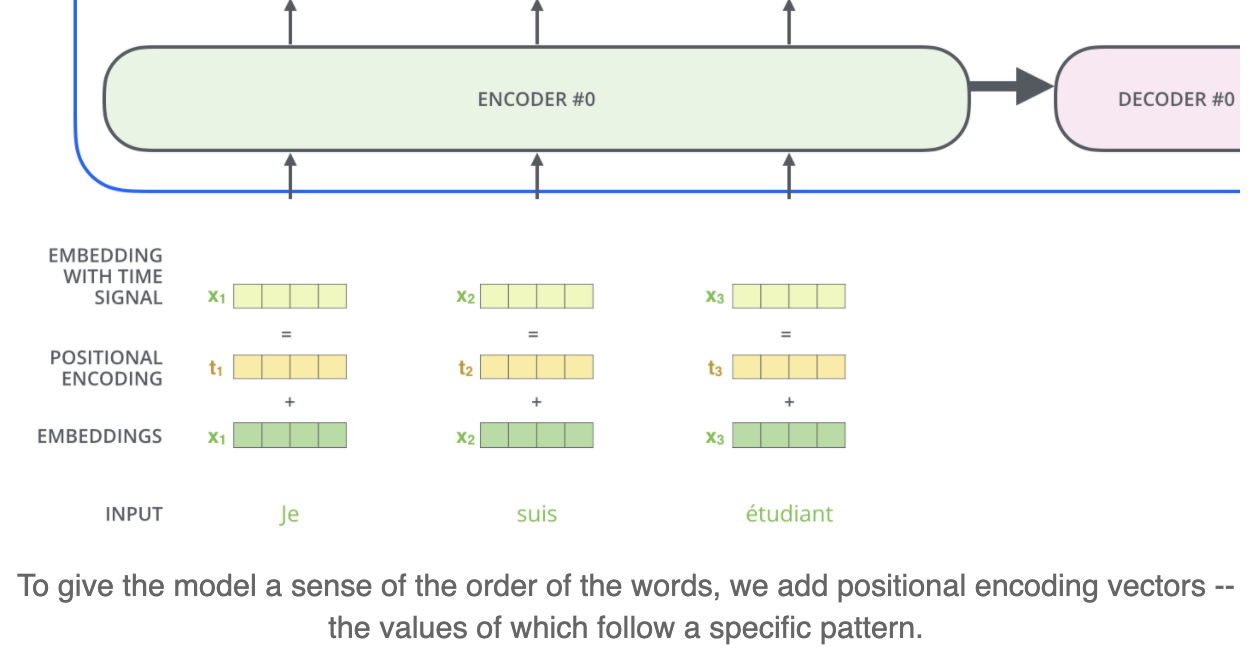
Position Encoding又称Position Embedding,也就是位置向量。谷歌给出构造Position Embedding的公式,而非让这个位置向量训练出来。

位置p映射为一个
词向量和位置向量的结合,既可以是拼接作为新向量;也可以把位置向量和词向量定义为一样的维度,然后二者相加。
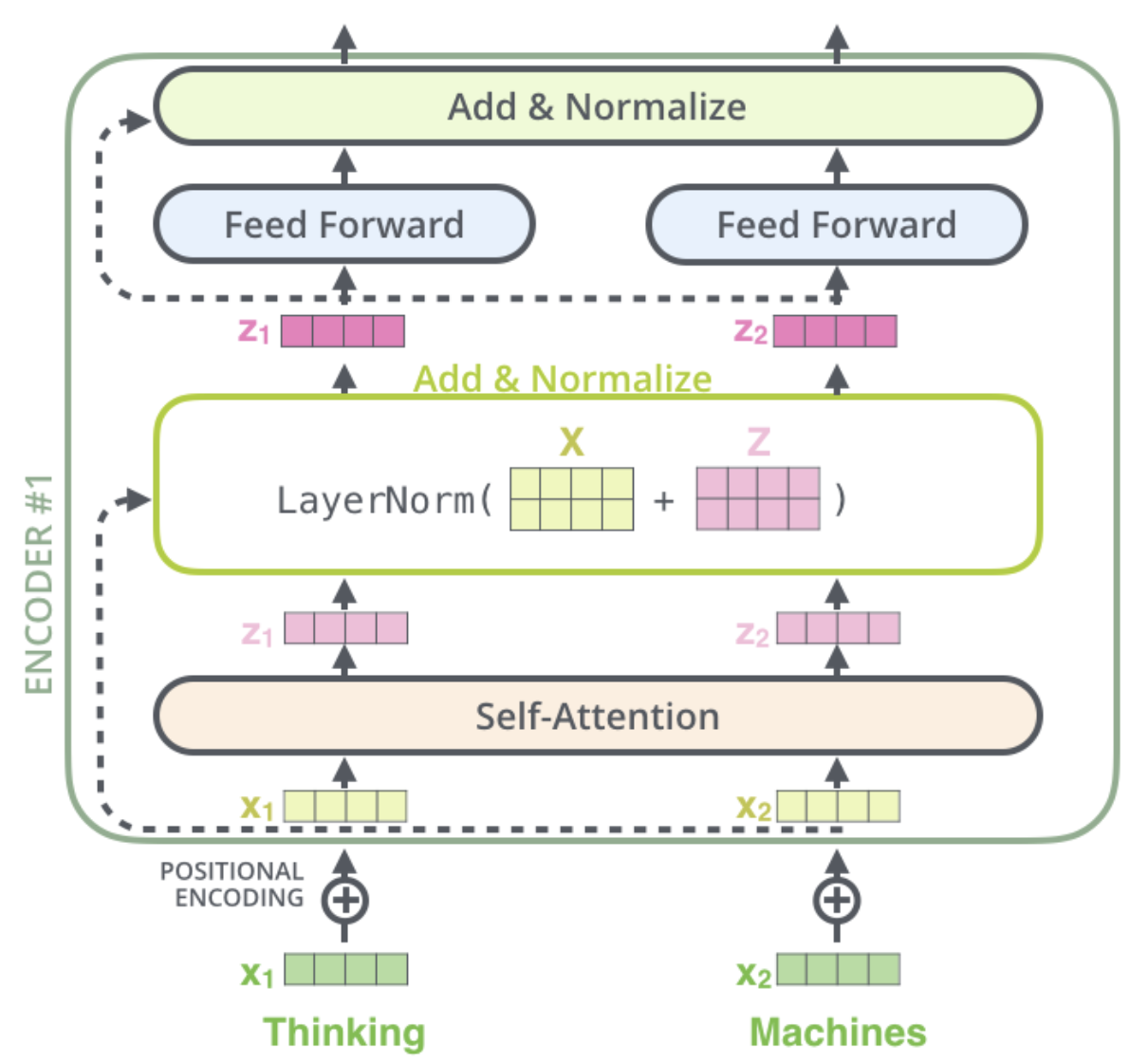
细节2:对每层结果归一化
在Encoder中的每一个self-attention层与ffnn层之后都会有一个Add&Normalize的过程,就是将X与Z相加后使用Layer Normalization归一化。
Decoders详解
encoders与decoders如何协同
Encoders的最后一层输出的结果会被转化为一组attention vectors K and V,这些会在decoder的encoder-decoder attention layer中被用来帮助decoder关注序列中的正确位置。
decoder的encoder-decoder attention layer的运作机制就和muti-headed self-attention类似,只不过他的K和V从encoder来,而Q从它下面的layer获得。
因此,encode和decoder中都存在注意力机制,但是encoder中的注意力机制被强调为自注意力(self-attention),但decoder中的注意力机制参考了encoder中的K和V的结果。
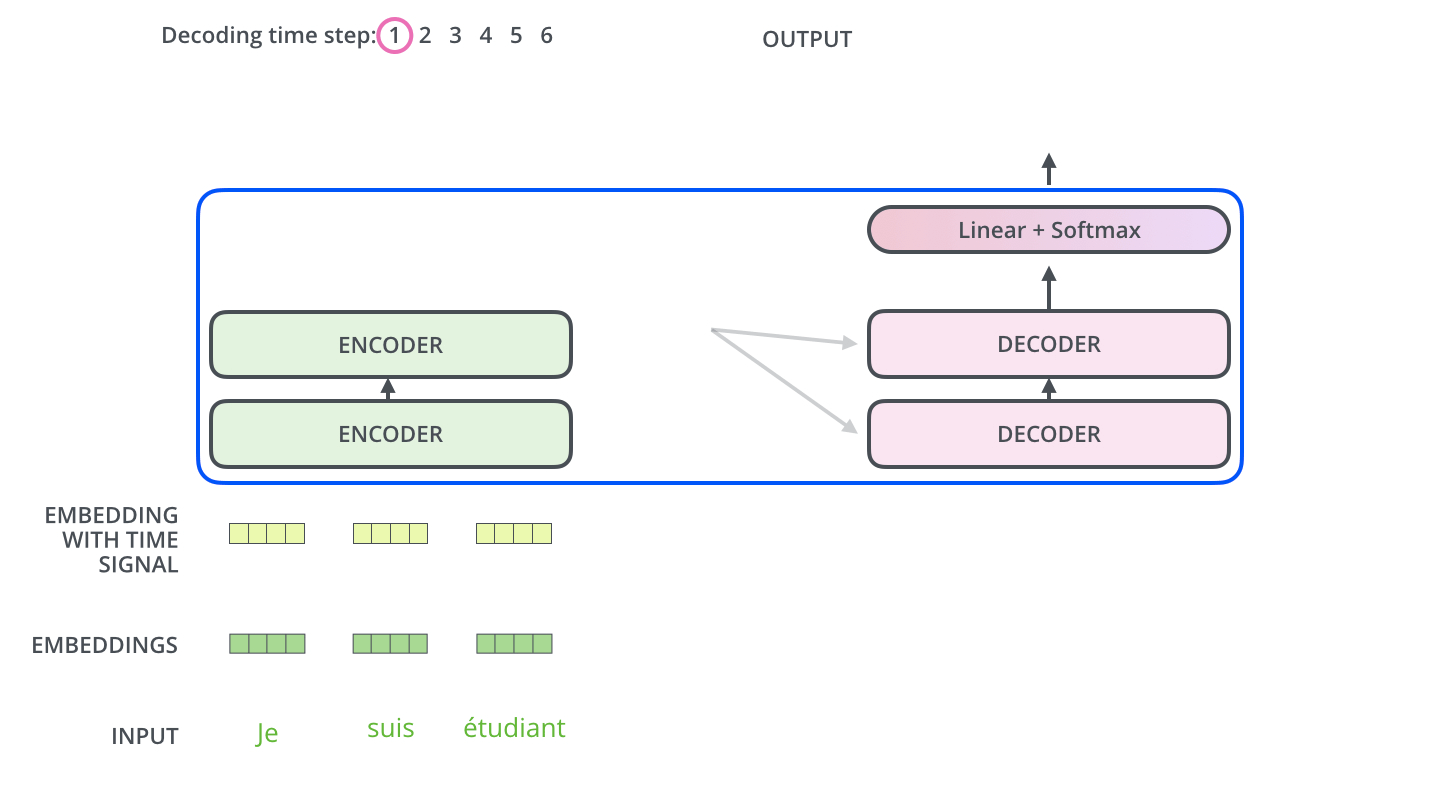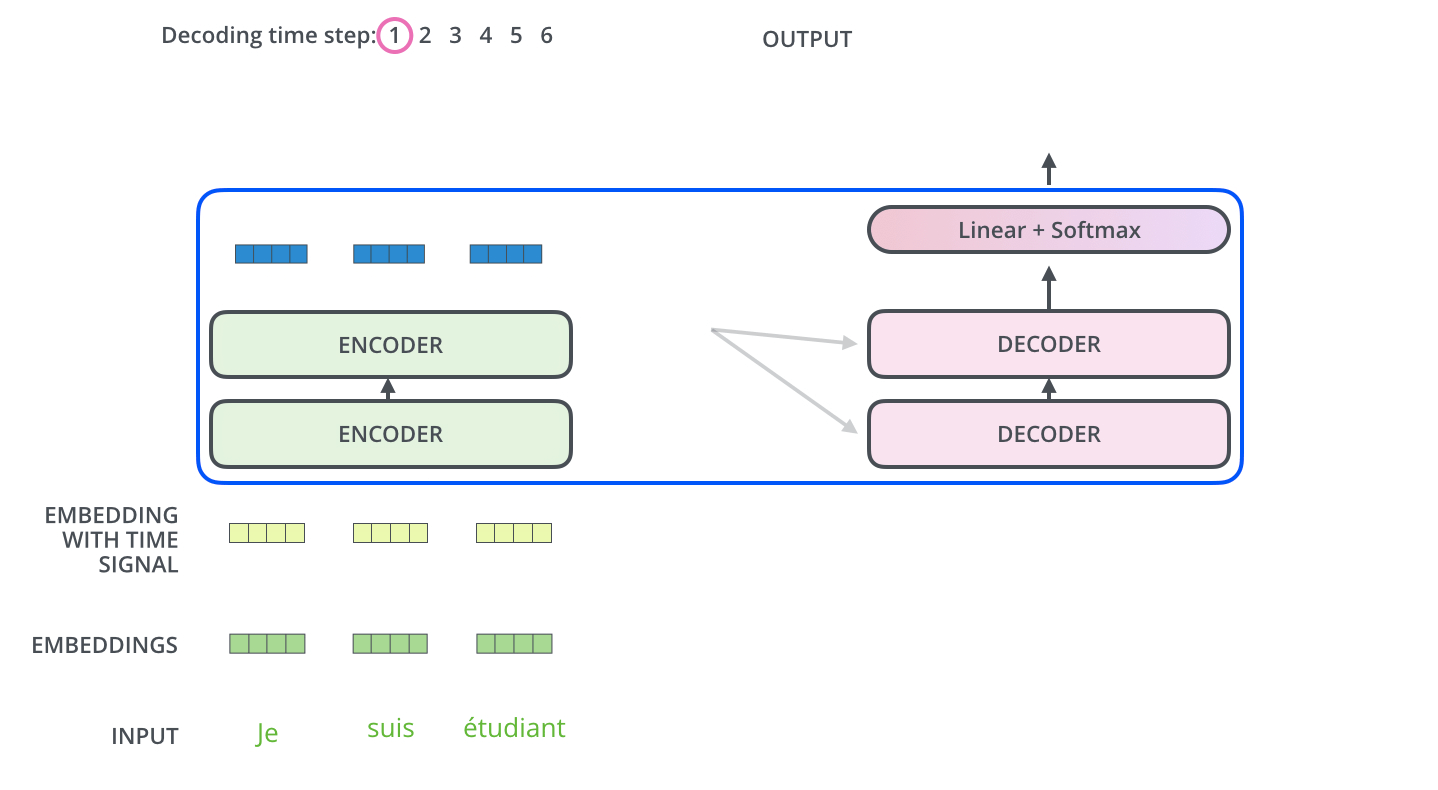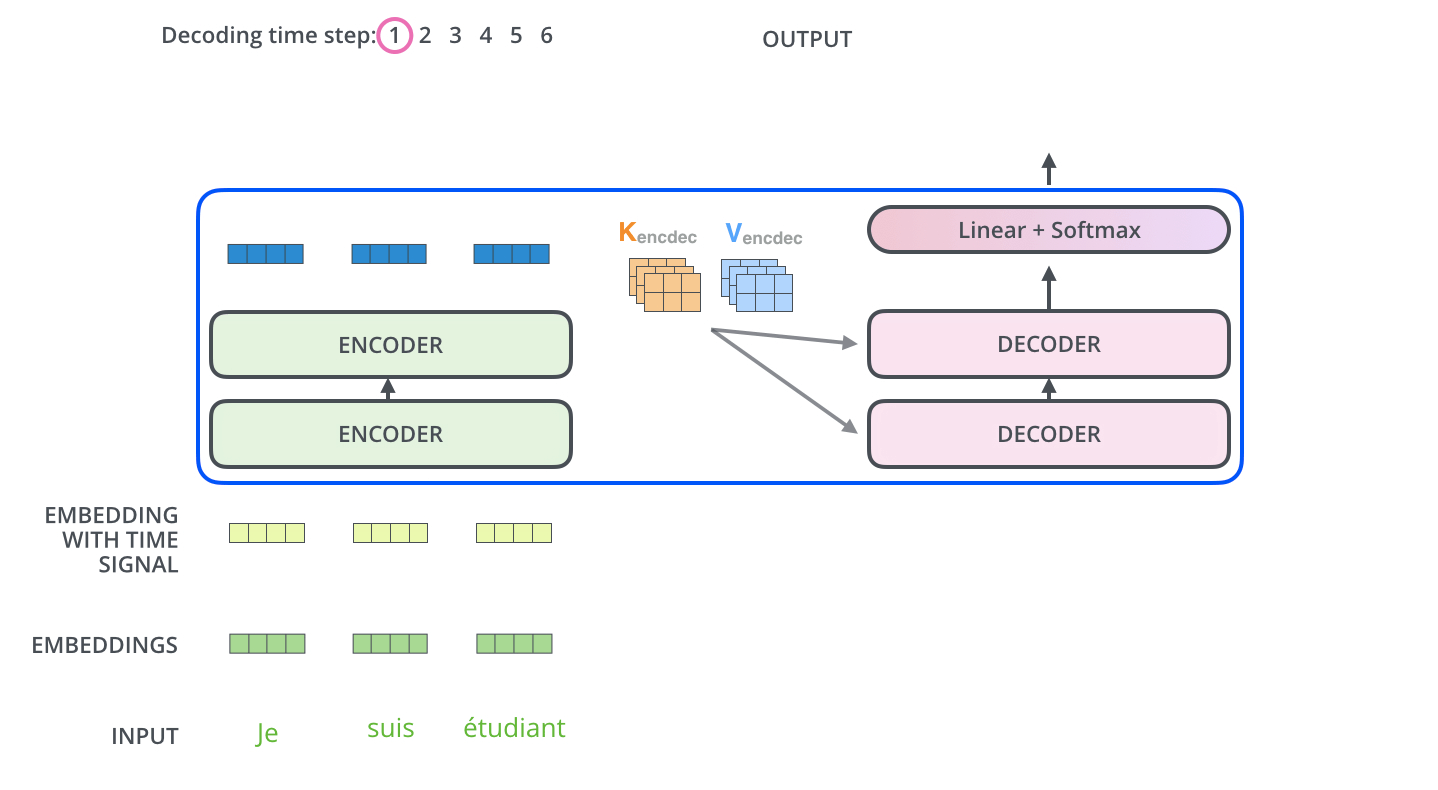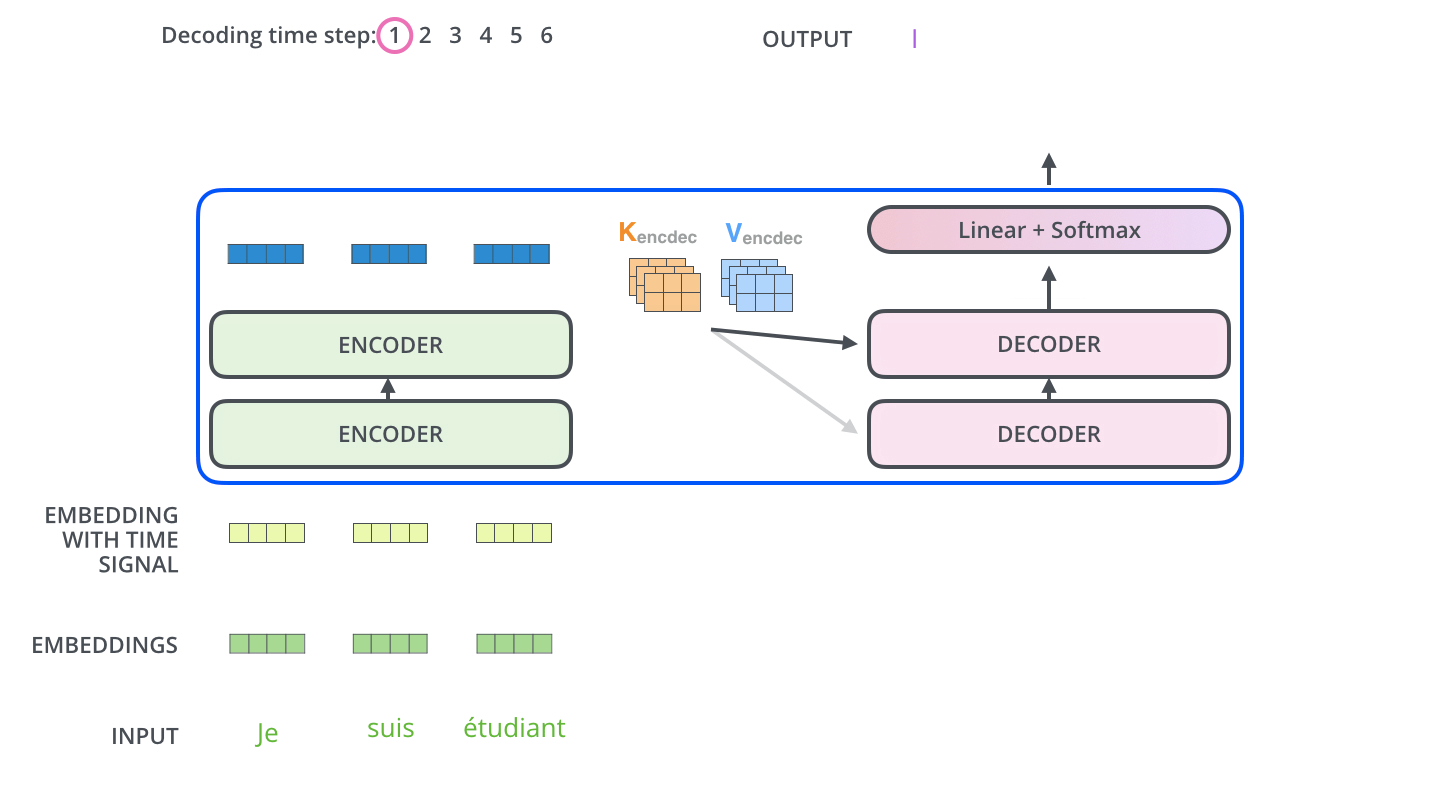
在最后一层Decoder输出了一个单词之后,这个单词又会作为输入进入到第一层Decoder。
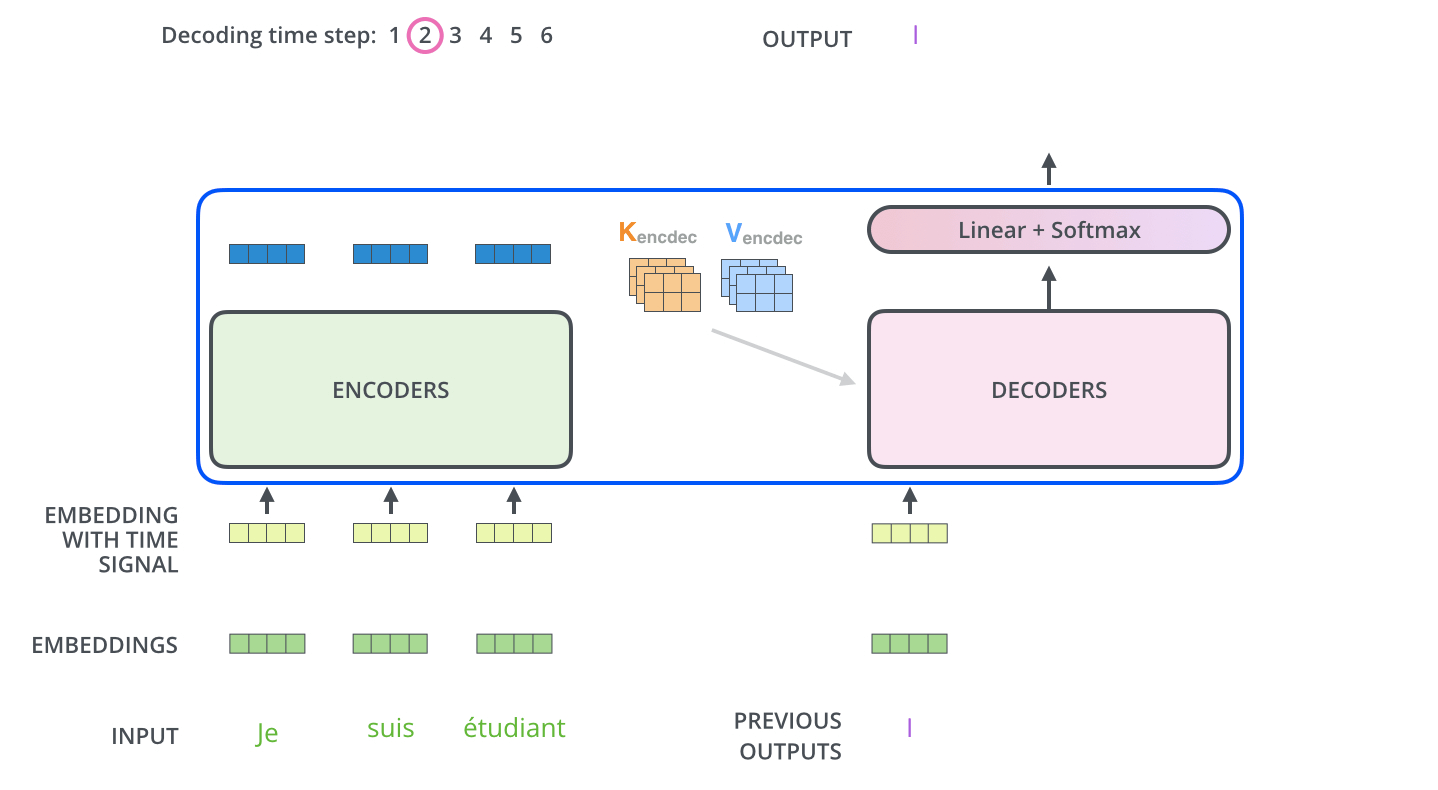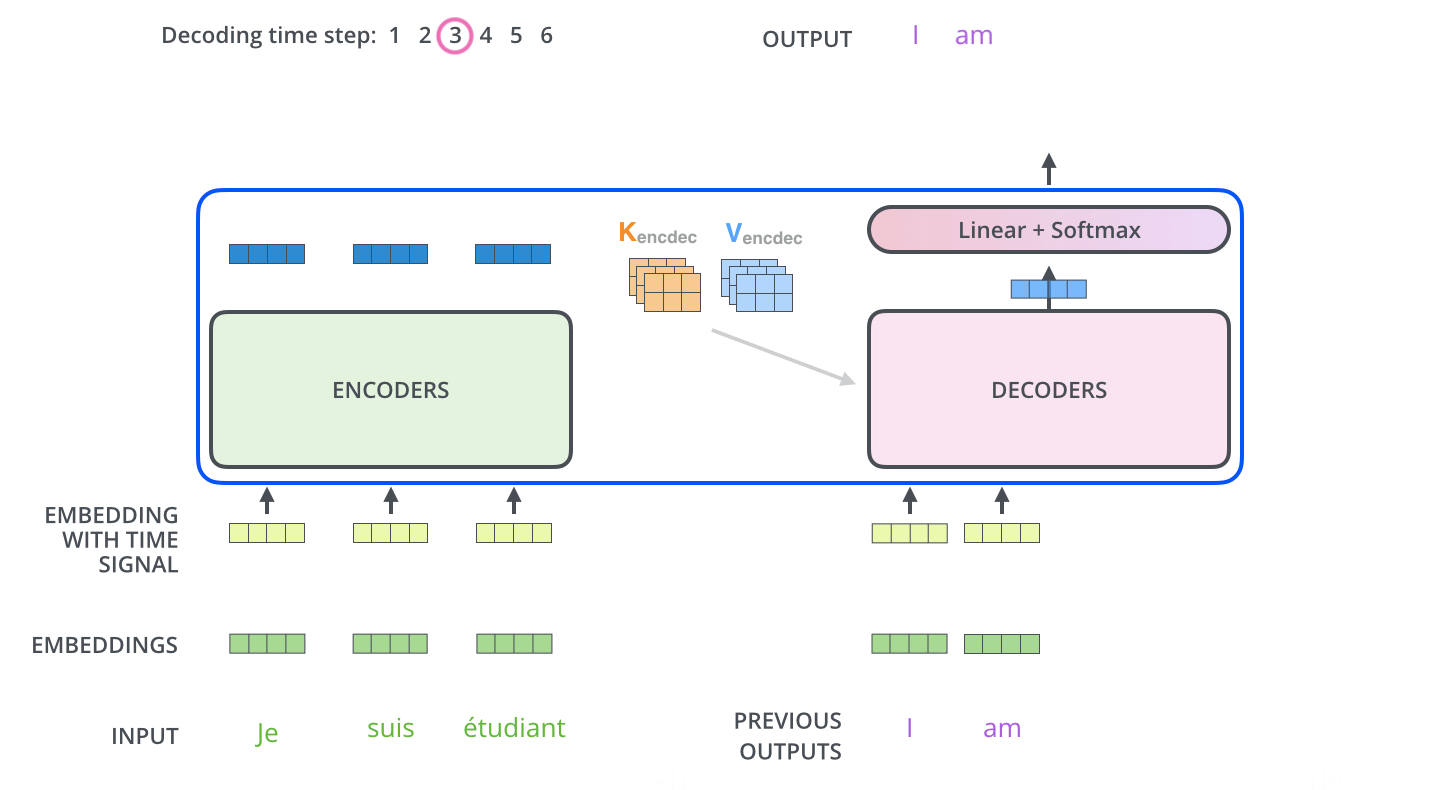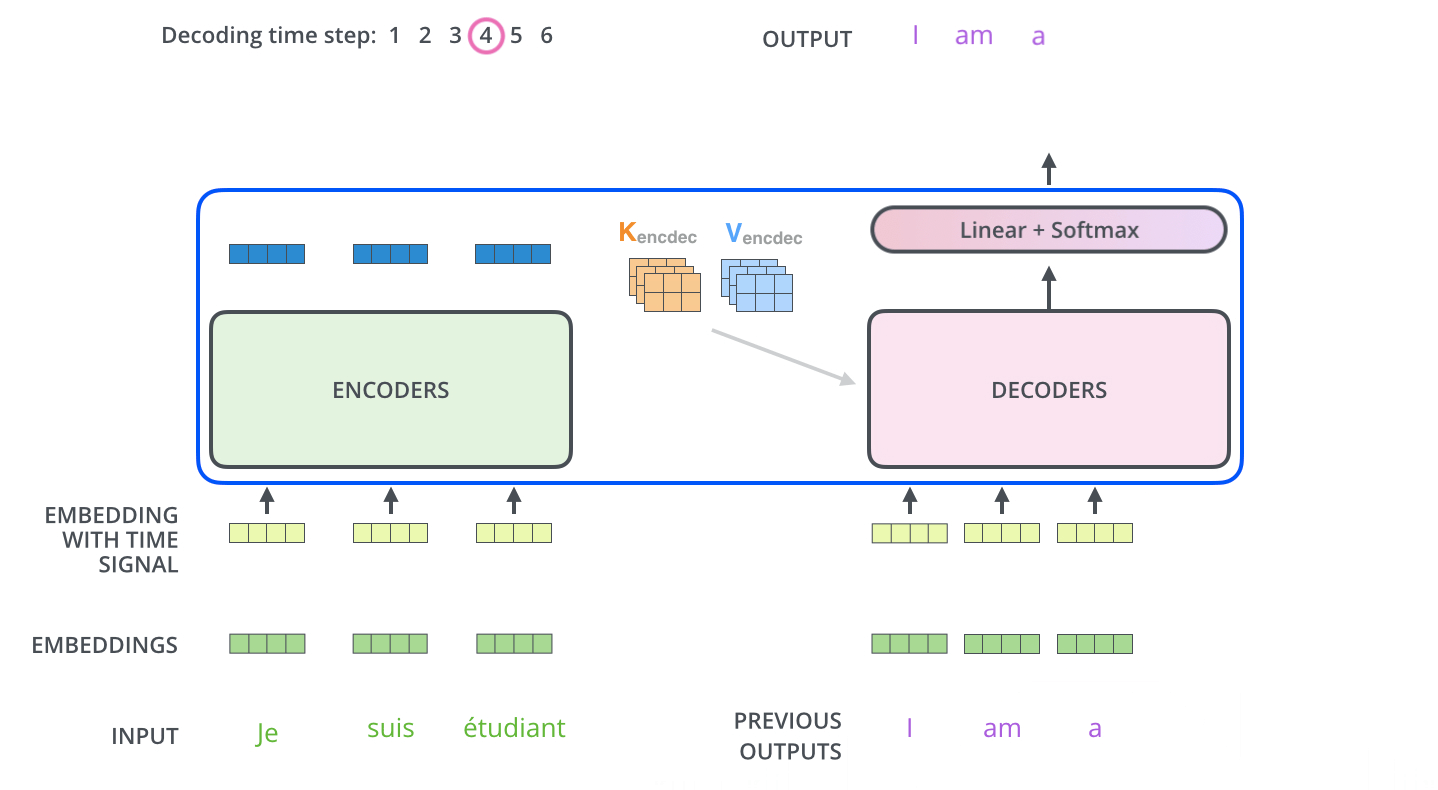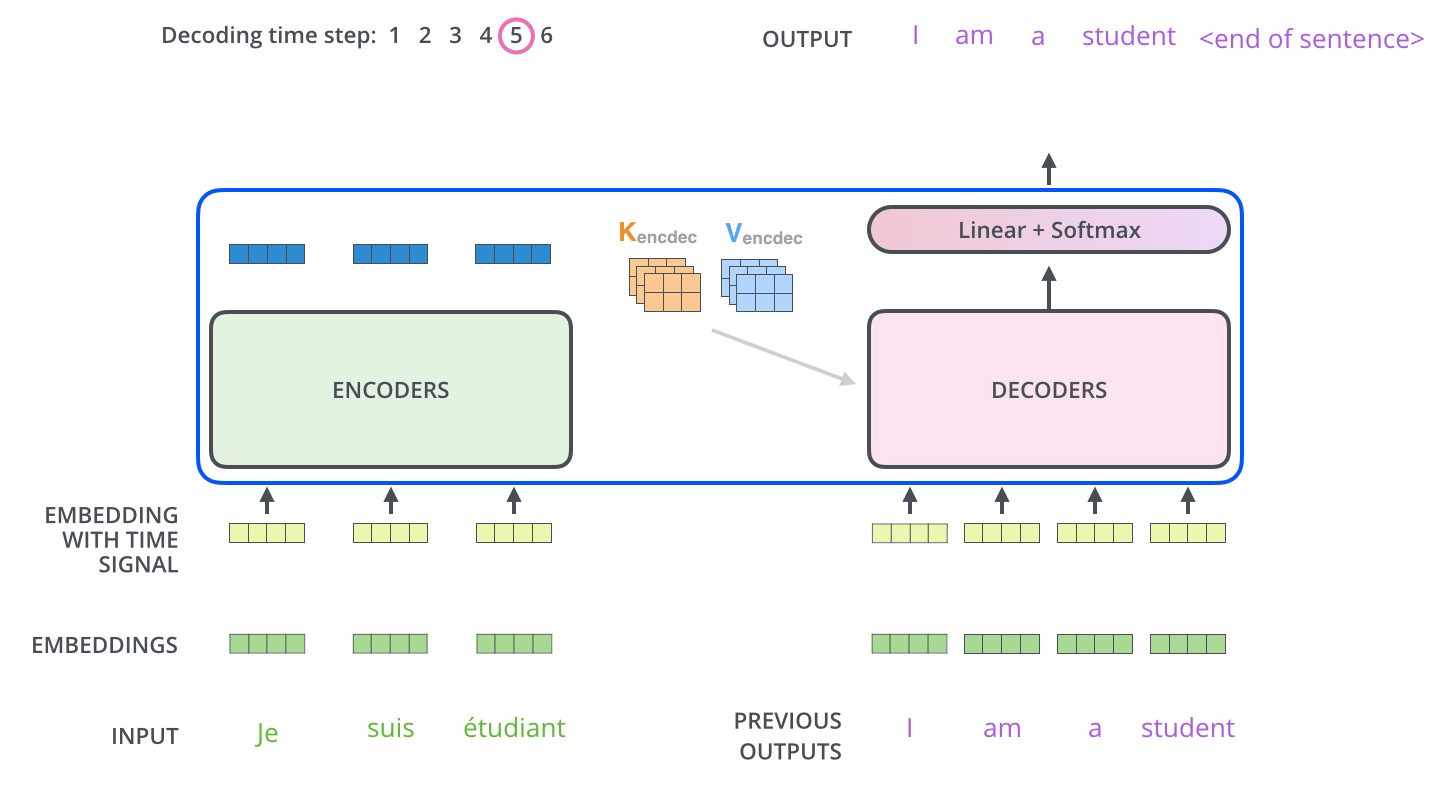
self-attention的区别
与Encoder中的self-attention不同的是,decoder中的self-attention只允许检查到已经输出的previous output的位置,对于未来的输出的位置将他们设置为-inf进行mask。
结束工作:Linear+softmax
decoder的输出就是a vector of floats,如何将这些向量转变为word,是Linear Layer和Softmax Layer的工作。
Linear Layer是一个简单的全连接网络fully connected neural network。它将decoder输出的vector投影到一个十分巨大的向量,名为logits vector。如果我们的模型经过训练有1w个不同的词汇量,那么logits vector就会是1w维度那么大,每一个维度的数值都对应了词汇量的每一个单词。
Softmax的工作就是把logits vector的数值转换成对应的概率(all positive, all add up to 1.0),最大概率的维度会被选中。
参考
- 本文标题:Transformer与Attention原理
- 本文作者:徐徐
- 创建时间:2021-03-11 15:01:26
- 本文链接:https://machacroissant.github.io/2021/03/11/illustrated-transformer/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!