
如何量化一个词
方法总的来说又两种,分别是one-hot representation与distributional representation。
one-hot表示方法虽然十分直观,但问题在于如果词汇量很大,每一个单词用向量来表示的dimension就十分大,所有词汇的one-hot向量组成的矩阵是sparse的。
distributional representation的方法在于它通过在每一个dimension上都有取值,从而实现词向量dimension的降低。并且单词变成词向量后,可以通过向量的加减法来实现词意的变化。
词向量的算法有skip-gram与Continuous Bag of Words(CBOW)两种。训练方法主要有hierarchical softmax与negative sampling两种。
给定词的上下文词的概率公式
自然语言处理当中的原始概率计算公式为:
其中
这个式子有何数学含义?分母是两个向量的点积。有
Softmax function: Standard map from
to a probability distribution softmax为什么叫softmax?soft+max,max因为它将大的值更强化了比重,soft因为它仍然考虑较小的值而不知和max函数一样直接抹去它的存在。它的作用类似于max函数,式子的形式有点像求一个数的exp占总体比例的大小。分母的求和是normalize to give probability。
参数说明
V/vocabulary:词表中的词数量,
d/dimension:每个词表示为多少维度的向量。
m:代表window size,每一个center word向前向后考虑m个单词。
CBOW
CBOW是用window outside word来预测center word的模型。模型的输入是one-hot context word vector
未知的量的定义如下。首先是两个矩阵
模型架构
第一步,为落在window size中的context word生成one-hot word vector ,共2m个
第二步,将input word matrix与one-hot context word vector相乘获得embedded word vectors,如单个词的结果为
这就是Keras等框架中所谓的embedding层,以one-hot为输入、中间层节点维字向量维数的全连接层,全连接层的参数就是一个字向量表。
因为one-hot型矩阵与其他矩阵相乘,操作就相当于查表,而不是真正的矩阵运算,所以运算量很低。
如果我们把2m个one-hot向量放在一起组成一个维度为
第三步,将所有第二步获得的vectors求平均,
第四步,生成一个score vector,
第五步,将score vector中的每一个cell值用softmax变为probability,
第六步,将
如何训练
现在我们已经知道了在拥有input word matrix和output word matrix的情况下,模型如何运作了。但是如何获得这两个矩阵,如何学习到这些参数呢?通常我们希望从一个实际存在的概率分布中学习到一个概率分布模型,我们通过减小实际分布与概率分布模型的距离来找到最优解。这里使用cross entropy
对于这个例子,我们输出的向量是一个one-hot向量,可以去掉sum符号。在下面这个式子中,我们用
因此我们的目标函数就是:
skip-gram
skip-gram是用center word来预测window outside word的模型,和CBOW的区别是,CBOW中的输入
模型架构
第一步,生成输入的center word的one-hot vector
第二步,将input word matrix
第三步,由于输入向量只有一个,不像CBOW一样需要averaging,直接令
第四步,用input word matrix
第五步,使用softmax将score转为概率
第六步,我们希望产生的
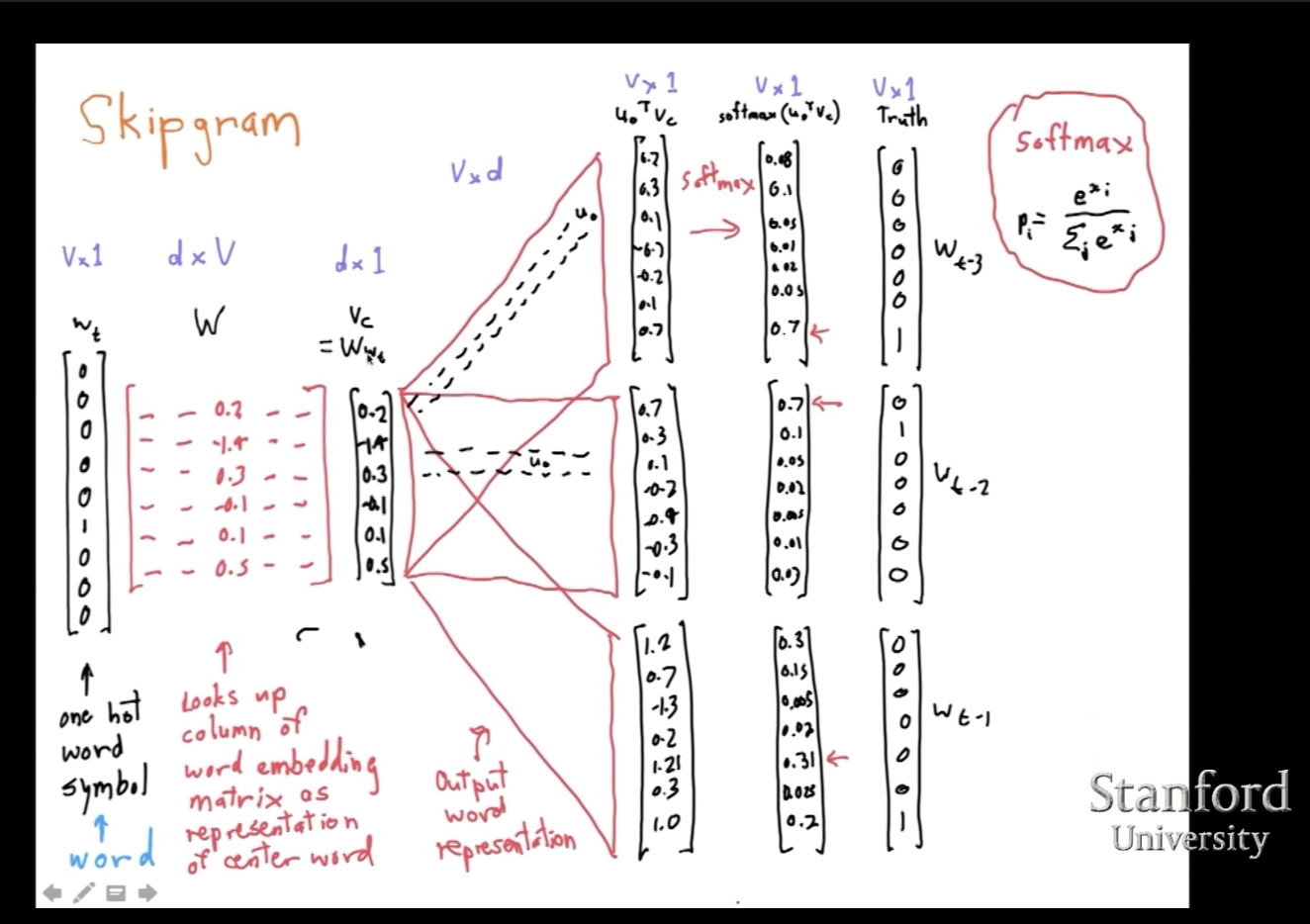
如何训练
首先定义两种类型的单词,一个是center word
以skip-gram为例,我们希望从center word
这里的
用log把乘积转变为和,并把max转换成min。
结合原始概率计算公式,对目标函数的
分前后两个式子分别观察,可以看到log和exp是相互抵消的,对矩阵求微分。
对于第二个式子,对最外层的log函数使用链式法则,需要注意应用了链式法则的sum中参数由w变为x,因为已经不是同一个了。
现在单独考虑partial开始的式子,将partial符号放到sum符号后面,对每一项求partial,并且在此应用链式法则。
将这个结果放回第二个式子中,可以得到
注意到分母是一个常数,因此可以进一步化简为
我们发现eq2中sum的对象形似softmax,可以看作是所有context vector
总的求偏微分后的结果为
怎么理解这个式子?主要由两部分组成,第一项是正确的target word的positive reinforcement,第二项是词表中所有其他词汇的一个negative reinforcement,意义是服从
训练优化方式
我们注意到
下面所有的优化,都在尝试用其他方法逼近softmax的效果。大致有两种方向。第一种是在softmax的基础上改良,如hierarchical softmax。第二种是以sampling为基础的新方法,这种方法完全抛开了softmax层,但效果和softmax一样好,如negative sampling和noise contrastive sampling。
注意!sampling-based approach只能在训练的时候去使用,在验证的时候还是需要老老实实使用softmax。
While the approaches discussed so far still maintain the overall structure of the softmax, sampling-based approaches on the other hand completely do away with the softmax layer. They do this by approximating the normalization in the denominator of the softmax with some other loss that is cheap to compute.
nce loss/noise contrastive estimation
NCE loss的直观想法就是把多分类问题转化为二分类问题,词表中的每一个word都代表着一个class,随着词汇量的增多,就要求模型具备从好多个class判断的能力,计算量非常大。为了实现不计算所有class的probability,但同时能在训练时给予一个合理的loss,这就引入了NCE loss。
NCE做的就是让模型具备区分真实数据和噪声做出来的假数据的能力,和GAN有点相似。对于每一个单词$wi
我们要实现一个二分类的任务,因此需要需要给每一个正确的单词
NCE loss function
因此重新定义目标函数NCE loss function。为了避免计算每一个word的概率,使用蒙特卡洛近似用均值去代替原式子中的期望。

接下来尝试表示损失函数中的概率P。因为label y可能来自两个分布,并且一个真实的(x,y)对会跟随k个噪声分布产生的虚假的(x, y’)。因此有如下式子:
于是,可以计算给定
由于是二分类问题,label y=0的概率就是
由于实际上我们并无法获得真实训练数据的分布
因此,可得
注意到,
将分母用
把
代入NCE loss function可以获得最终的结果。
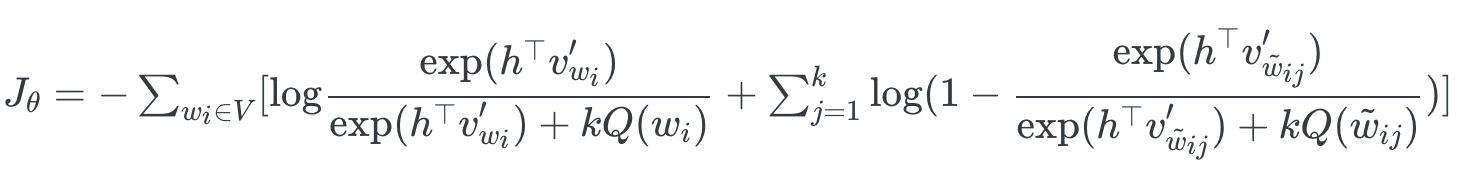
文章存疑?:It can be shown that as we increase the number of noise samples kk, the NCE derivative tends towards the gradient of the softmax function.
negative sampling/NEG
每一个训练阶段,不要遍历所有的词汇,而是采几个负样本。思想是We “sample” from a noise distribution
和NCE不同的是,在计算the probability that a word
NEG直接把分母的
这么做的根据在哪里?第一,在极限情况
最终NEG loss function结果如下。
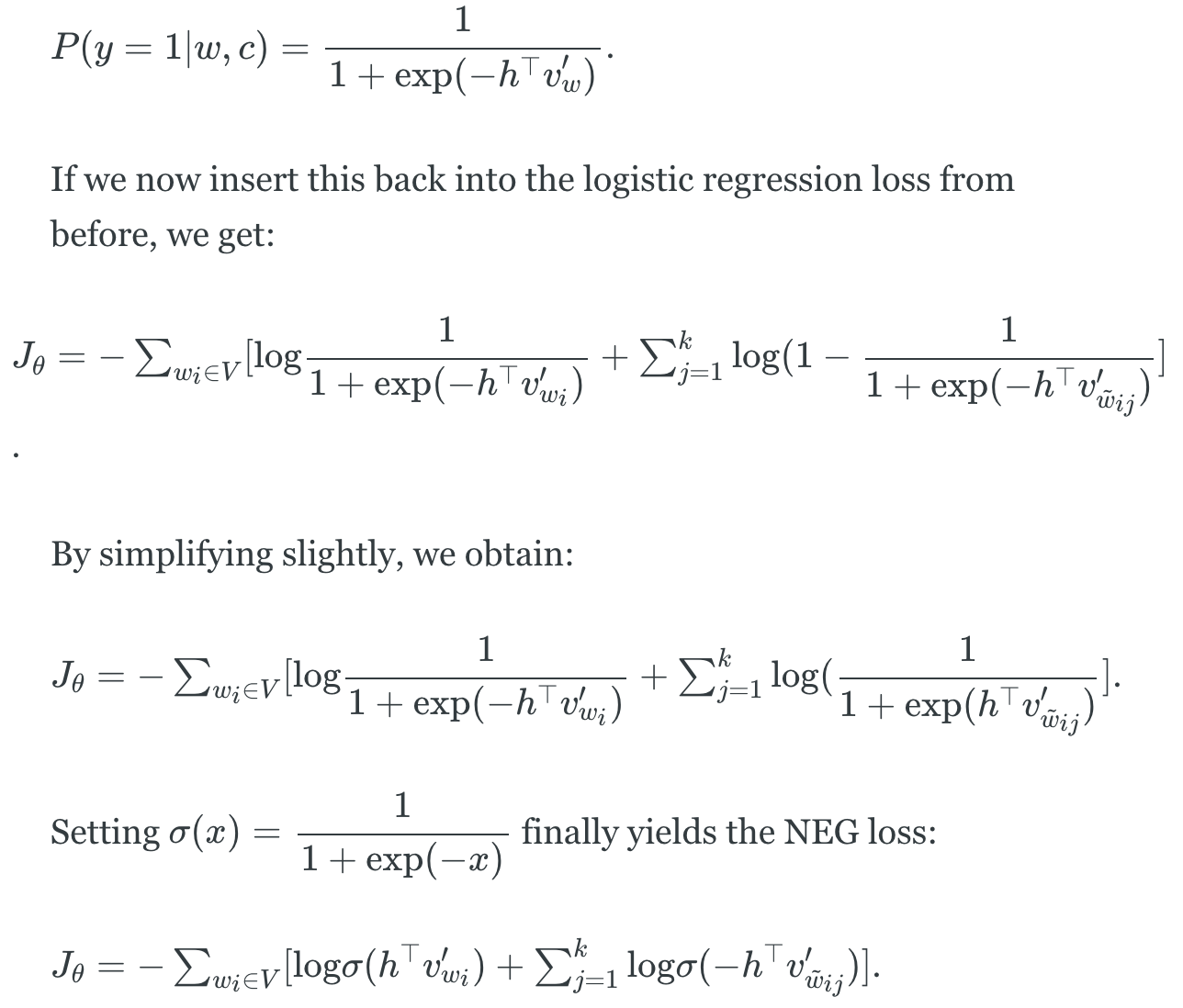
参考
word2vec初步认识
莫烦 Python教学 Continuous Bag of Words (CBOW)
word2vec架构解析
word2vec是如何得到词向量的? - crystalajj的回答 - 知乎
word2vec训练优化
Understanding tf.nn.nce_loss() in tensorflow
On word embeddings - Part 2: Approximating the Softmax
softmax与交叉熵的关系
word2vec、词向量、Embedding层
- 本文标题:Word2Vec原理、训练与优化
- 本文作者:徐徐
- 创建时间:2021-03-16 13:47:16
- 本文链接:https://machacroissant.github.io/2021/03/16/word2vec/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!