
Bert的预训练任务有两个。第一,Masked Language Model(MLM),也就是让模型预测masked word。第二,Next Sentence Prediction(NSP),也就是让模型判断句子A后面否是直接跟着句子B。执行这些任务的模块最终都会从预训练模型中移除,所需要的只是训练权重,因此这些预训练任务又被叫做fake tasks。
所谓下游任务(Downstream Task),就是在Bert等预训练模型之后接一些针对特定任务的网络结构,在训练的时候微调(fine-tune)已有参数,即可适应当前任务。
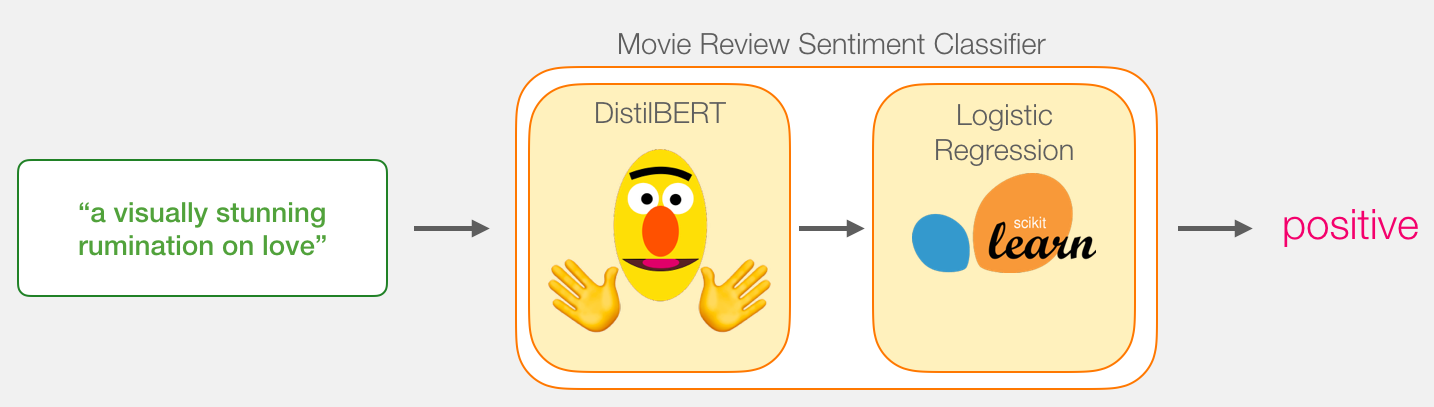
文本二分类Demo
使用SST2数据集进行文本二分类,数据格式如下:
| sentence | label |
|---|---|
| a stirring , funny and finally transporting re imagining of beauty and the beast and 1930s horror films | 1 |
我们希望使用DistilbBert的预训练模型(已经训练好了权重),后接一个scikit-learn提供的二分类器,输出与label相匹配,1代表positive,0代表negative。
使用transformer库加载预训练模型,可以使用from_pretrained()方法实例化一个预训练模型的权重与预训练模型的分词器。
1 | import transformers as ppb |
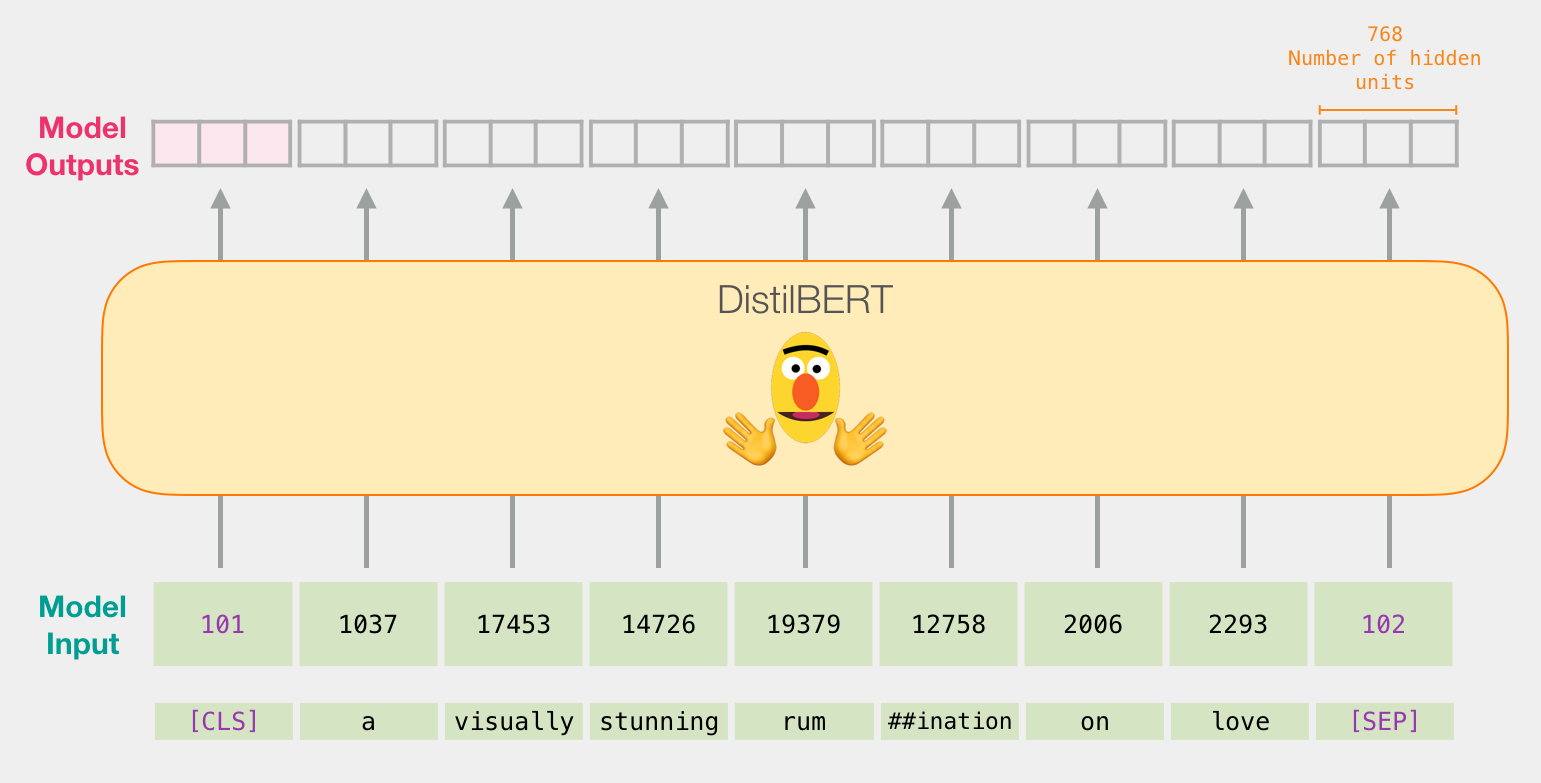
预训练的DistilBert会将SST2中的sentence都变成setence embedding,需要如下步骤:
- 将句子转变为token
- 在句子中添加
[CLS]和[SEP]这样的special tokens,他们会随着模型一起训练,其实最后做分类的时候,分类的结果就是[CLS]。 - 从embedding table中将每一个token都用对应的id替换,替换后的句向量(其实算不上句向量,这只是词向量的简单拼接,并没有语义)就能作为DistilBert的输入了。
token是怎么对应到id的?id又怎么映射到768维度的向量?
实际上bert拥有自己的词汇量,这个词汇量是一个词典dictionary,该词典的key就是每个token的id,该词典的value就是与该token对应的vector。假设bert有30k的词汇量,那么bert在做tokenize的时候就会从一个储存了30k个维度为768向量的词典中去对应该token的id。
如果某个单词不在bert的词汇量内怎么办?subword tokenization会让复杂单词先分解再去查表找id。

以上三个步骤对应到代码就只有简短的一句话:
1 | tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True) |
我们输入的数据是形状为2000*2的矩阵batch_1,其中2000代表有200条数据,2代表有两列,第一列index=0是sentence,第二列index=1是label。对这个矩阵做完tokenize前后的内容分别是:
1 | # tokenize前 |
由于句子长度本身就不一样,tokenize后句子长短不一,因此要做padding,找出这2000条句子中tokenize后长度最长的作为总长度,不满这个长度的每条句子后面就补满0,获得padded矩阵。
1 | [101 1037 18385 1010 6057 1998 2633 18276 2128 16603 1997 5053 1998 1996 6841 1998 5687 5469 3152 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] |
但是padding后的张量不能直接传入BERT,这会影响attention的计算结果,因此我们要创建一个mask矩阵,让预训练模型忽略padding的部分。这个attention-mask矩阵就是一个维度和padded矩阵完全相同的1-0矩阵。
1 | array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]) |
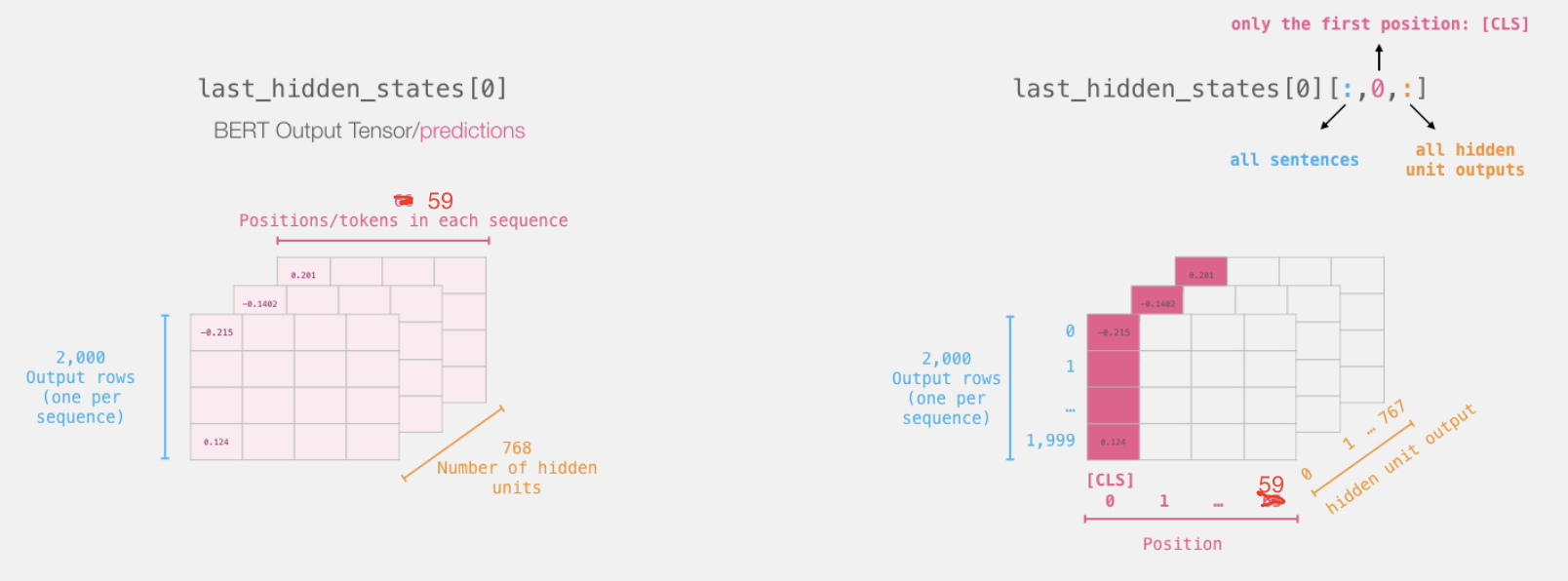
输入进预训练模型的句子,最终输出的每一个token都是同一个emb_size=768,且padded后的长度59,那么一个句子就要用59个维度位768的向量来表示。
这样的句子有2000个,也就是2000个768行66列的矩阵从上往下堆叠在一起。顶层标有数字的从前向后的那一行,就是训练好的CLS,它可以看作是整个句子的句向量;它的后一行就是第一个句子的第一个单词的词向量,维度为768。
阅读理解Demo
这里引入了segment embedding的概念。参考自文章Question Answering with a Fine-Tuned BERT,youtube也有视频,colab中也有代码。
在使用Bert做阅读理解的时候,句子对输入由问题和包含答案的文本组成,形式为[CLS] query [SEP] reference,这一部分输入称为token embeddings。还有segment embeddings,主要用于区分两种句子,有0和1组成;对于只有一个句子的任务,用来区分真正的句子和句子padding的内容。还有position embeddings,用于保留每个token的位置信息。
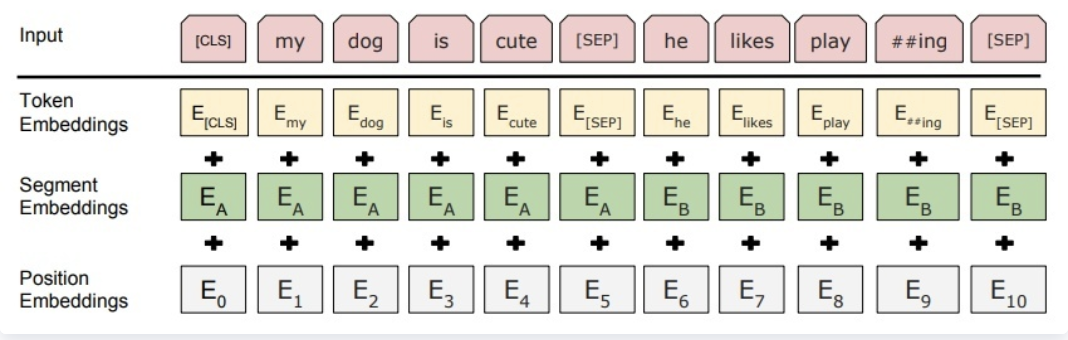
BERT在训练的时候,input embeddings就是token embeddings, segmentation embeddings和position embeddings的总和。
BERT的output 是每个token的encoding vector。
tokenizer方式总结
在跟着二文本分类的Demo做的时候我就发现,图中演示的Tokenize的过程,并不是直接将句子变成words,也就是说token并不等于words,比如rumination就被拆分成了rum和##ination两个部分。token只是按照某种规则将句子拆分多个部分的结果——spliting a text into smaller chunks。
一种最简单的tokenize就是利用空格分词,将标点符号也作为一个token;如果直接把puctuation标点与单词放在一起,就会出现同一个单词有不同的embedding的问题(如Transofrmer? & Transformer.)。这被叫做space and punctuation tokenization/词粒度。
还有一种方式就是利用字母分词——tokenize on characters/字粒度。虽然这样很简单且能降低复杂度,但是这对模型学习语义没有好处。
Transformer中用到的tokenize的方式就是取上面两种方法的混合—— a hybrid between word-level and character-level tokenization called subword tokenization,也就是subword tokenization/subword粒度。
subword tokenization的准则就是常用词不会被分为更小的chunk,少见词应当被分解为有意义的subword。例如annoyingly可以被理解为annoying和ly这两个subword的组成。
例如BertTokenizer会将“I have a new GPU”变为如下分词。
1 | >>> from transformers import BertTokenizer |
其中,GPU被分解为gp和##u,##代表了这个subword前面要跟着其他subword才能组成有意义的单词。
所有的subword都以##开头。
为了更好地理解BERT Vocabulary,可以参考这个代码笔记Inspect BERT Vocabulary。在加载开源的BERT预训练模型的时候可以载入与该模型匹配的Tokenizer,通过for token intokenizer.vocab.keys()循环输出就可以得到BERT的所有词汇量,共计30552个。组成如下:1-999号分别是保留位,除了特殊意义的1-[PAD],101-[UNK],102-[CLS],103-[SEP],104-[MASK],其他都是unused;1000-1996号都是单个char;从1997开始的所有单词似乎都是按照出现频率由高到低排序的,如the就在1997号。
参考
A Visual Guide to Using BERT for the First Time
NLP领域中的token和tokenization到底指的是什么? - ICY星星的回答 - 知乎
- 本文标题:Bert下游任务
- 本文作者:徐徐
- 创建时间:2021-04-08 17:22:35
- 本文链接:https://machacroissant.github.io/2021/04/08/bert-downstream-task/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!